Introduction#
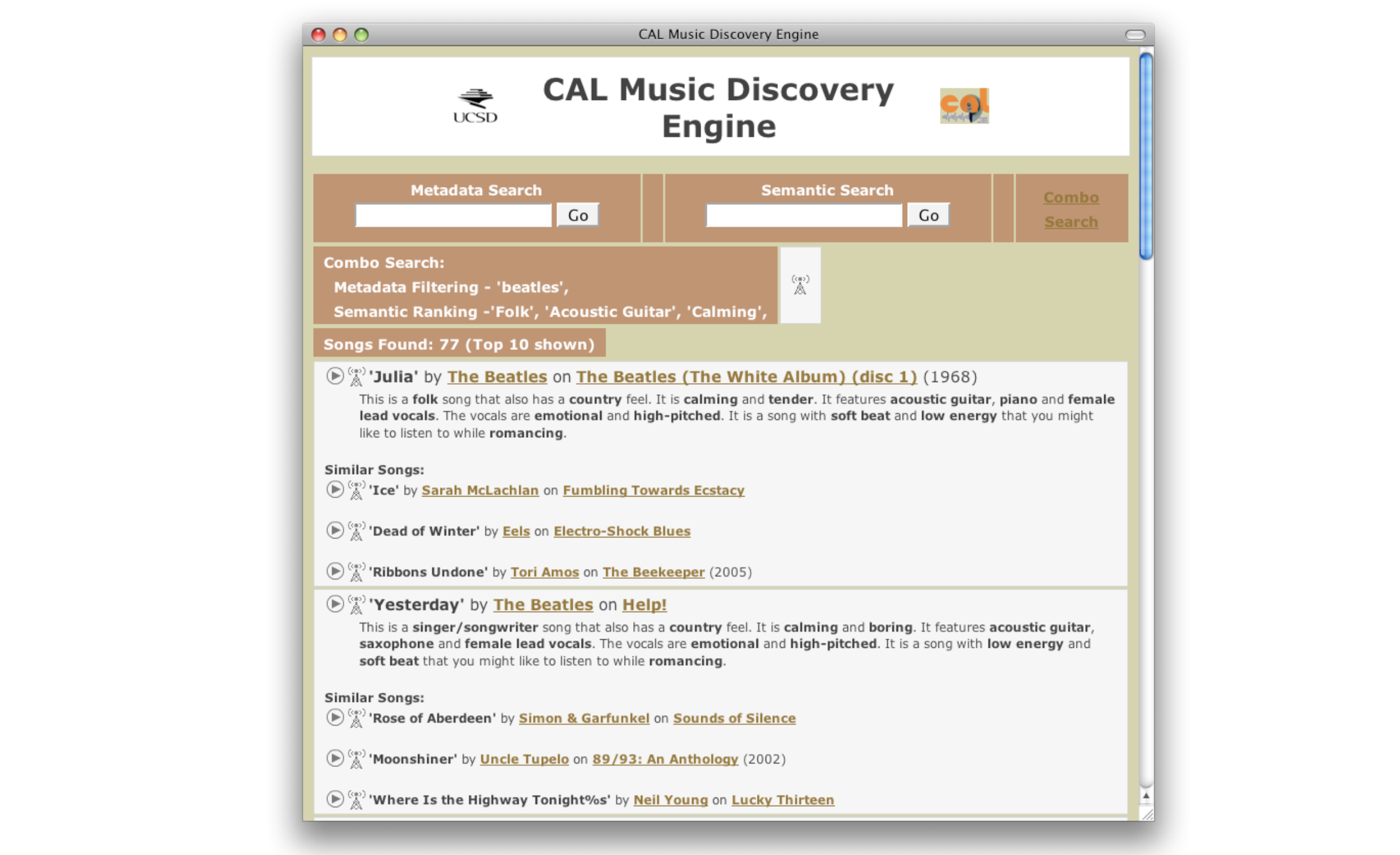
Music retrieval is the task of finding a set of music pieces that match a given query. This query can take various forms - it could be musical attribute descriptions (e.g., “happy upbeat pop song”), metadata information (e.g., “Oasis - Don’t Look Back in Anger”), or a similarity query (e.g., similar to Oasis). The system analyzes the query and searches through a music database to return relevant results that best match the search criteria. The retrieved results are typically ranked by their relevance or similarity to the query. This technology enables users to discover music in more intuitive and flexible ways compared to traditional catalog browsing. Music retrieval systems need to bridge the semantic gap between high-level query descriptions and low-level audio features, making it a challenging problem in music information retrieval.
Early Text-to-Music Retrieval has been studied for a long time under the names “query-by-text” [TBTL08] or “query-by-description” [Whi05]. As previously explained, the initial systems were built using Supervised Classification.
Note
“query-by-text” system can retrieve appropriate songs for a large number of musically relevant words. … we describe such a system and show that it can both annotate novel audio content with semantically meaningful words and retrieve relevant audio tracks from a database of unannotated tracks given a text-based query. We view the related tasks of semantic annotation and retrieval of audio as one supervised multiclass, multilabel learning problem. [TBTL08]
Early Stage Retrieval Methods#
Early retrieval methods were based on supervised classification models. The classification models are trained on labeled datasets where human annotators have tagged tracks with the appropriate attributes. Each classifier learns to recognize the audio characteristics associated with its target labels (e.g., what makes a song sound like “rock” or like an Oasis song). In this approach, music tracks are first annotated with relevant attributes through initial tagging tasks like genre classification (e.g., “rock”, “jazz”, “classical”) and instrument recognition. These annotations create a structured vocabulary of labels that can be used for retrieval.
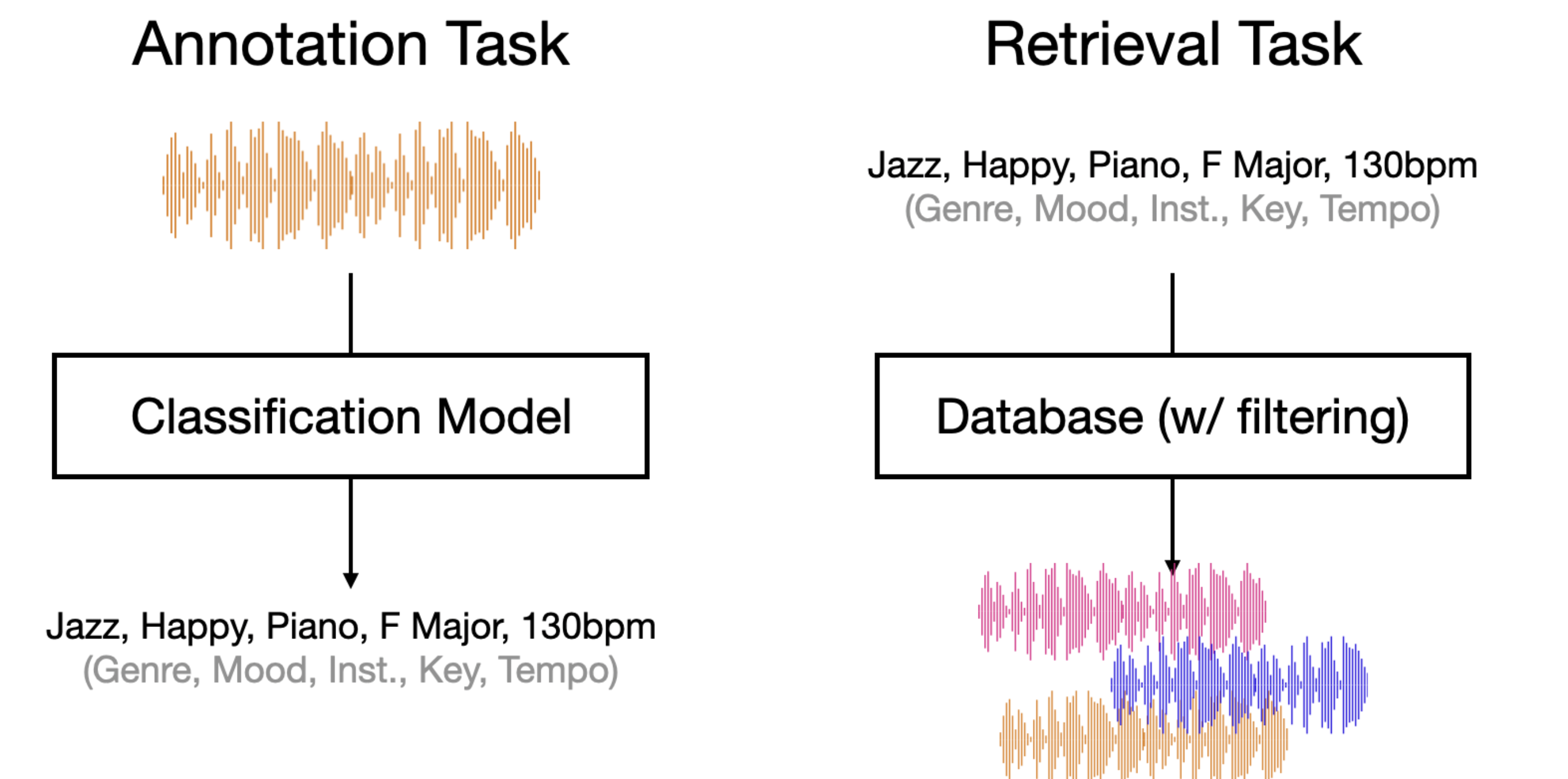
During the retrieval stage, there are two main ways to search through the annotated music collection:
Filtering-based boolean search: This method treats each attribute as a binary filter. For example, a query like “rock songs by Oasis” would first filter for tracks labeled as “rock” genre, then filter that subset for tracks labeled with “Oasis” as the artist. Multiple filters can be combined using boolean operators (AND, OR, NOT).
Output logits based ranking: This approach uses the output logits from the classification models. Rather than just using binary yes/no filters, it ranks tracks based on the raw logit values (pre-softmax activation values) from the classifier’s final layer. These logit values indicate the model’s assessment of each attribute before normalization, providing a more granular scoring mechanism for ranking tracks.
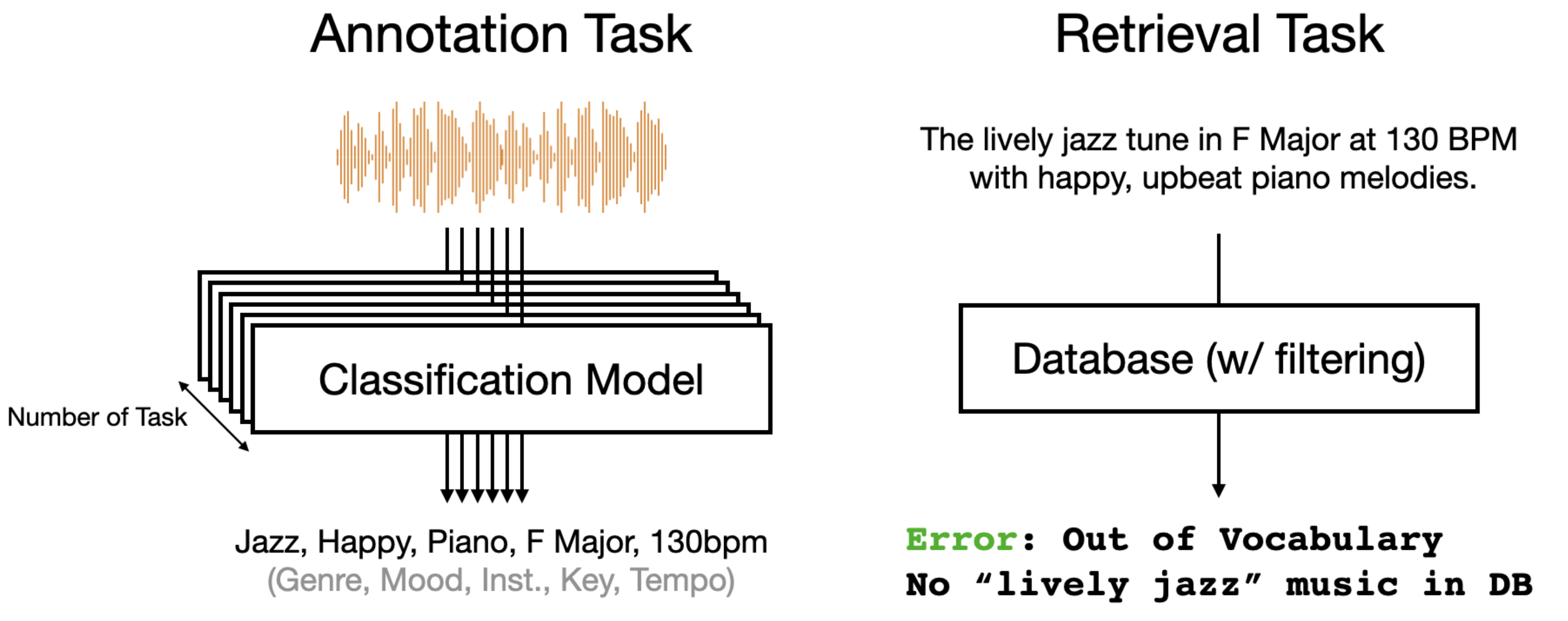
Problem: Out of Vocabulary#
However, the classification-based retrieval framework faces two significant challenges. First, since we need to train task-specific classification models, we require separate models for each distinct musical attribute (i.e., genre classification, instrument recognition, mood detection, key estimation, tempo prediction, etc.). Managing multiple classifier models leads to increased computational overhead and inference costs. Additionally, as our music database expands, the annotation costs grow proportionally since each new track needs to be processed by all these different models.
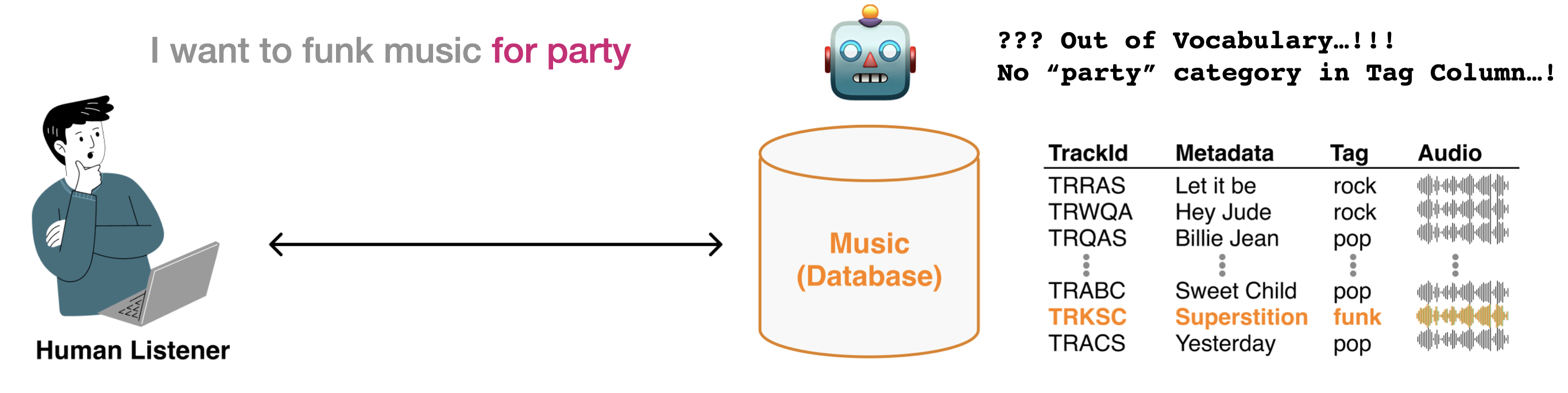
Second, there is a critical limitation regarding vocabulary coverage. The datasets typically used for training these classifiers contain a very restricted vocabulary, usually ranging from only 50 to 200 words. This creates what is known as the Out-of-Vocabulary (OOV) problem - when users attempt to search using terms that fall outside this limited vocabulary, the system cannot process their queries. This becomes particularly problematic when dealing with the broader "open vocabulary problem," where users naturally want to describe music using unrestricted language. Attempting to address this through supervised classification would require developing an impractically large number of classification models to cover all possible query terms. The cost and complexity of creating and maintaining such a comprehensive system, along with the challenge of collecting sufficient training data for each new term, makes this approach unfeasible for real-world applications.
References#
Douglas Turnbull, Luke Barrington, David Torres, and Gert Lanckriet. Semantic annotation and retrieval of music and sound effects. IEEE Transactions on Audio, Speech, and Language Processing, 16(2):467–476, 2008.
Brian Alexander Whitman. Learning the meaning of music. PhD thesis, Massachusetts Institute of Technology, 2005.