Overview of Tutorial#
This tutorial will present the changes in music understanding, retrieval, and generation technologies following the development of language models.
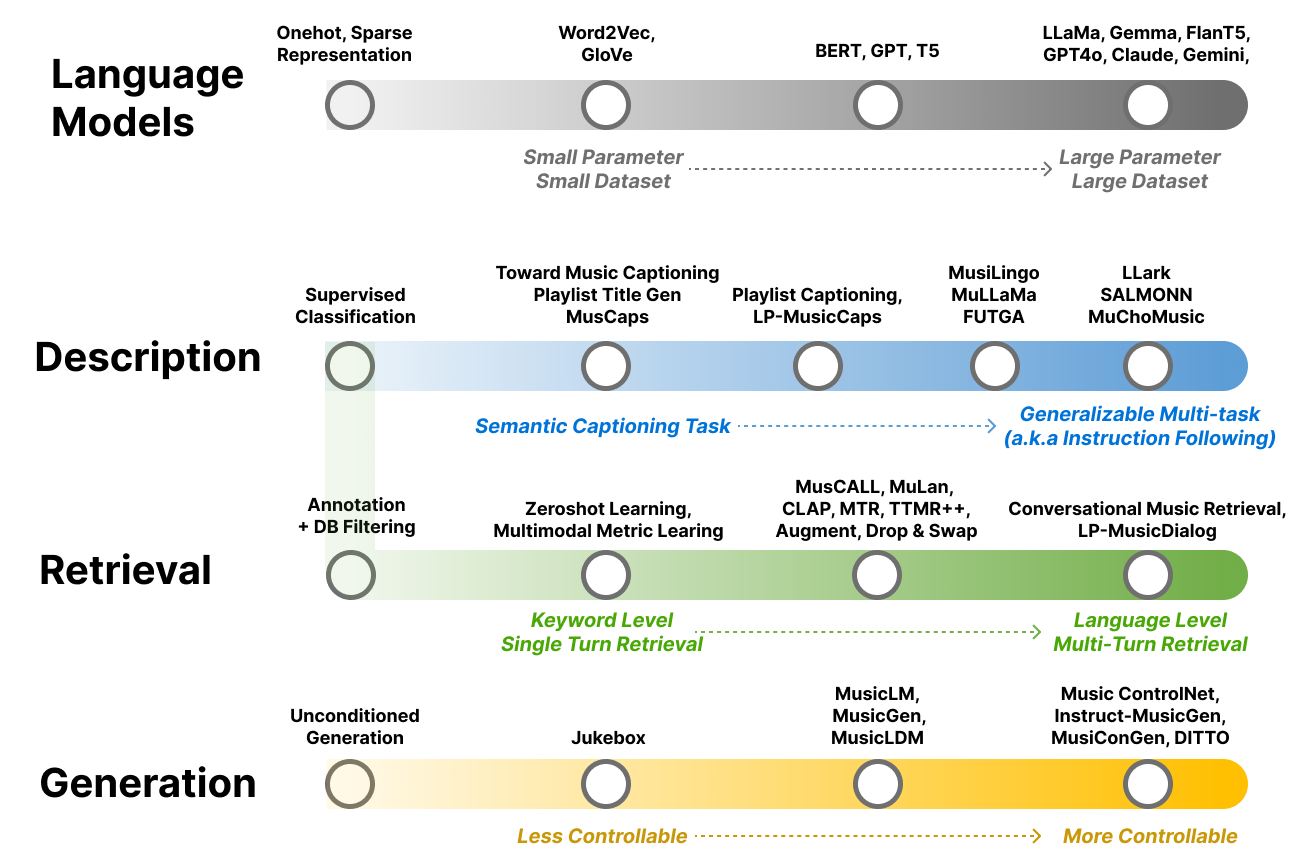
Fig. 3 Illustration of the development of music and language models.#
Langauge Models#
Chapter 2 presents an introduction to language models (LMs), essential for enabling machines to understand natural language and their wide-ranging applications. It traces the development from simple one-hot encoding and word embeddings to more advanced language models, including masked langauge model [DCLT18], auto-regressive langauge model [RWC+19], and encoder-decoder langauge model [RSR+20], progressing to cutting-edge instruction-following [WBZ+21] [OWJ+22] [CHL+24] and large language models [AAA+23]. Furthermore, we review the components and conditioning methods of language models, as well as explore current challenges and potential solutions when using language models as a framework.
Music Description#
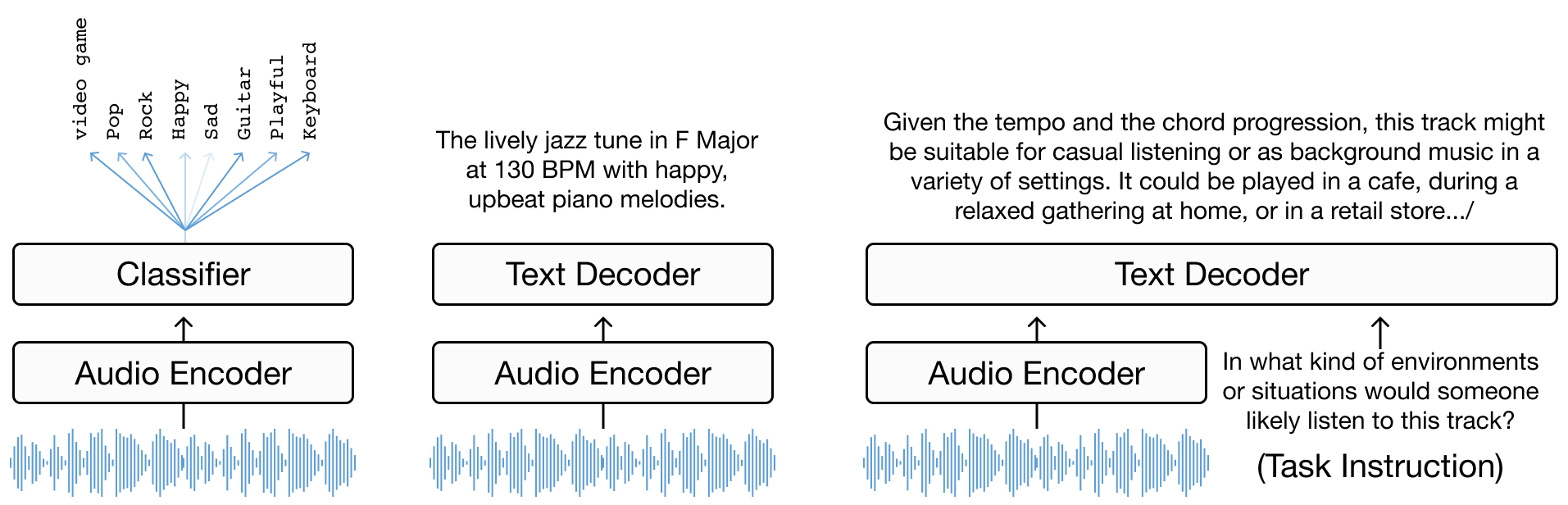
Chapter 3 offers an in-depth look at music annotation as a tool for enhancing music understanding. It begins with defining the task and problem formulation, transitioning from basic classification [TBTL08] [NCL+18] to more complex language decoding tasks. The chapter further explores encoder-decoder models [MBQF21] [DCLN23] and the role of multimodal large language models (LLMs) in music understanding [GDSB23]. The chapter explores the evolution from task-specific classification models to more generalized multitask models trained with diverse natural language supervision.
Music Retrieval#
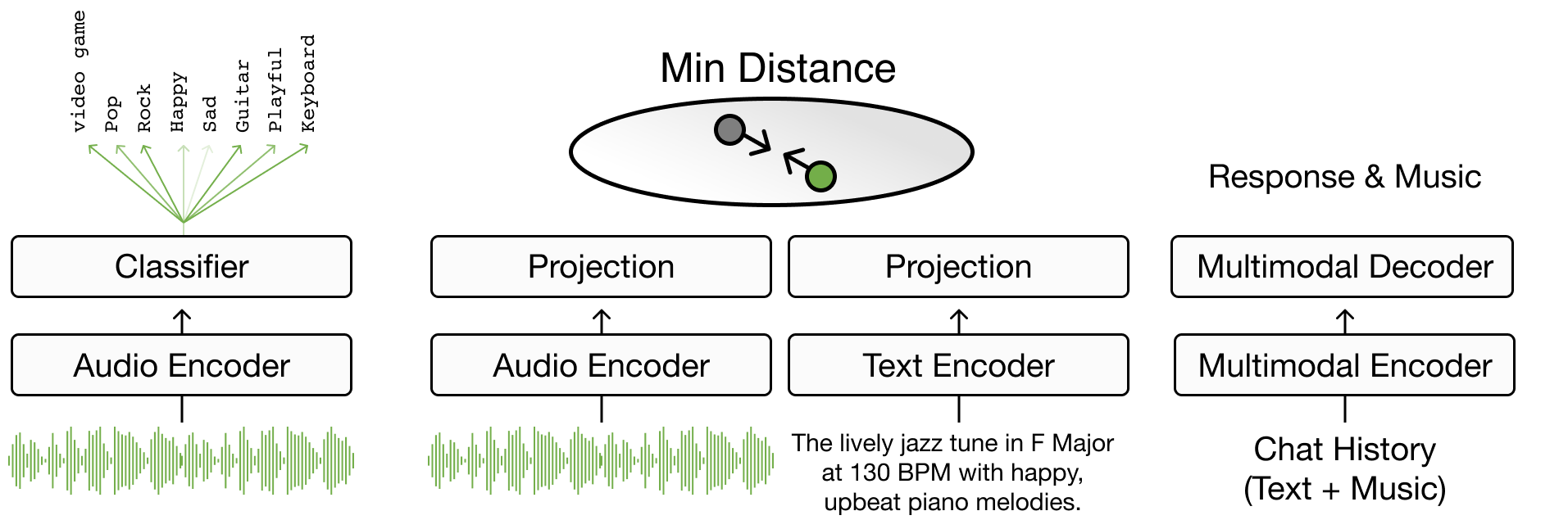
Chapter 4 focuses on text-to-music retrieval, a key component in music search, detailing the task’s definition and various search methodologies. It spans from basic boolean and vector searches to advanced techniques that bridge words to music through joint embedding methods [CLPN19], addressing challenges like out-of-vocabulary terms. The chapter progresses to sentence-to-music retrieval [HJL+22] [MBQF22] [DWCN23], exploring how to integrate complex musical semantics, and conversational music retrieval for multi-turn dialog-based music retrieval [CLZ+23]. It introduces evaluation metrics and includes practical coding exercises for developing a basic joint embedding model for music search. This chapter focuses on how models address users' musical queries in various ways.
Music Generation#
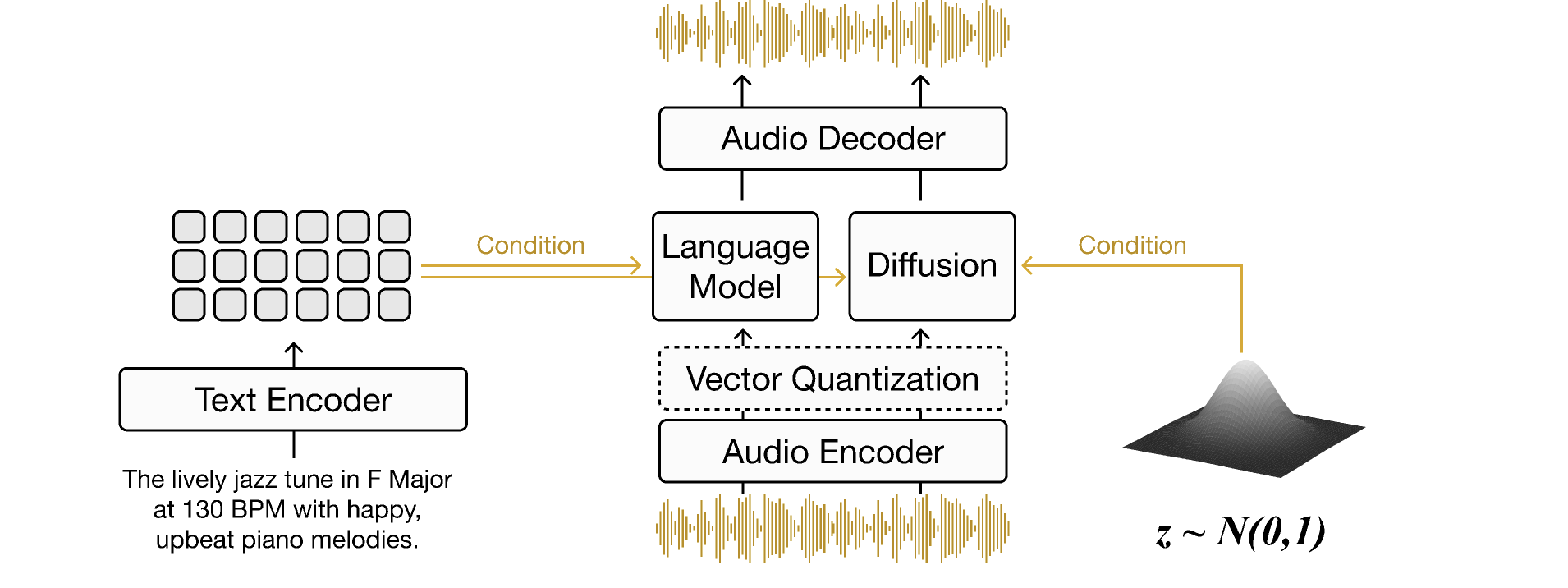
Chapter 5 delves into the creation of new music through text-to-music generation techniques, emphasizing the production of novel sounds influenced by text prompts [DJP+20]. It introduces the concept of generating music without specific conditions and details the incorporation of text-based cues during the training phase. The discussion includes an overview of pertinent datasets and the evaluation of music based on auditory quality and relevance to the text. The chapter compares music generation methods, including diffusion models [CWL+24] and discrete codec language models [ADB+23] [CKG+24]. Furthermore, it examines the challenges associated with purely text-driven generation and investigates alternative methods of conditional generation that go beyond text, such as converting textual descriptions into musical attributes [WDWB23] [NMBKB24].
References#
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, and others. Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023.
Andrea Agostinelli, Timo I Denk, Zalán Borsos, Jesse Engel, Mauro Verzetti, Antoine Caillon, Qingqing Huang, Aren Jansen, Adam Roberts, Marco Tagliasacchi, and others. Musiclm: generating music from text. arXiv preprint arXiv:2301.11325, 2023.
Arun Tejasvi Chaganty, Megan Leszczynski, Shu Zhang, Ravi Ganti, Krisztian Balog, and Filip Radlinski. Beyond single items: exploring user preferences in item sets with the conversational playlist curation dataset. In Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval. 2023.
Ke Chen, Yusong Wu, Haohe Liu, Marianna Nezhurina, Taylor Berg-Kirkpatrick, and Shlomo Dubnov. MusicLDM: enhancing novelty in text-to-music generation using beat-synchronous mixup strategies. In IEEE International Conference on Audio, Speech and Signal Processing (ICASSP). 2024.
Jeong Choi, Jongpil Lee, Jiyoung Park, and Juhan Nam. Zero-shot learning for audio-based music classification and tagging. In ISMIR. 2019.
Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Yunxuan Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, and others. Scaling instruction-finetuned language models. Journal of Machine Learning Research, 25(70):1–53, 2024.
Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi, and Alexandre Défossez. Simple and controllable music generation. Advances in Neural Information Processing Systems, 2024.
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018.
Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford, and Ilya Sutskever. Jukebox: a generative model for music. arXiv preprint arXiv:2005.00341, 2020.
SeungHeon Doh, Keunwoo Choi, Jongpil Lee, and Juhan Nam. Lp-musiccaps: llm-based pseudo music captioning. In International Society for Music Information Retrieval (ISMIR). 2023.
SeungHeon Doh, Minz Won, Keunwoo Choi, and Juhan Nam. Toward universal text-to-music retrieval. In ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 1–5. IEEE, 2023.
Josh Gardner, Simon Durand, Daniel Stoller, and Rachel M Bittner. Llark: a multimodal foundation model for music. arXiv preprint arXiv:2310.07160, 2023.
Qingqing Huang, Aren Jansen, Joonseok Lee, Ravi Ganti, Judith Yue Li, and Daniel PW Ellis. Mulan: a joint embedding of music audio and natural language. arXiv preprint arXiv:2208.12415, 2022.
Ilaria Manco, Emmanouil Benetos, Elio Quinton, and György Fazekas. Muscaps: generating captions for music audio. In 2021 International Joint Conference on Neural Networks (IJCNN), 1–8. IEEE, 2021.
Ilaria Manco, Emmanouil Benetos, Elio Quinton, and György Fazekas. Contrastive audio-language learning for music. arXiv preprint arXiv:2208.12208, 2022.
Juhan Nam, Keunwoo Choi, Jongpil Lee, Szu-Yu Chou, and Yi-Hsuan Yang. Deep learning for audio-based music classification and tagging: teaching computers to distinguish rock from bach. IEEE signal processing magazine, 2018.
Zachary Novack, Julian McAuley, Taylor Berg-Kirkpatrick, and Nicholas J. Bryan. DITTO: Diffusion inference-time T-optimization for music generation. In International Conference on Machine Learning (ICML). 2024.
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, and others. Training language models to follow instructions with human feedback. Advances in neural information processing systems, 2022.
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, and others. Language models are unsupervised multitask learners. OpenAI blog, 2019.
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of machine learning research, 21(140):1–67, 2020.
Douglas Turnbull, Luke Barrington, David Torres, and Gert Lanckriet. Semantic annotation and retrieval of music and sound effects. IEEE Transactions on Audio, Speech, and Language Processing, 16(2):467–476, 2008.
Jason Wei, Maarten Bosma, Vincent Y Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M Dai, and Quoc V Le. Finetuned language models are zero-shot learners. arXiv preprint arXiv:2109.01652, 2021.
Shih-Lun Wu, Chris Donahue, Shinji Watanabe, and Nicholas J Bryan. Music controlnet: multiple time-varying controls for music generation. arXiv preprint arXiv:2311.07069, 2023.