Introduction#
What is music description? And why do we need it?#
The goal of automatic music description (AMU) is to analyse music audio and “translate” it into human-readable form. As such, AMU is an umbrella term that covers several tasks.
Being able to automatically create descriptions of music audio content is useful for a variety of practical purposes. For example, through AMU we can:
Annotate large collections of music for easier search, navigation and organisation
Generate human-readable summaries of musical content for the Deaf or Hard-of-hearing, or when audio playback is not possible
Automatically caption music sections in videos and films
Produce educational resources
Enable personalised music recommendation systems using natural language queries
In the last couple of years, AMU systems have also represented an increasingly popular resource for synthetic data generation. In this case, instead of finding a direct application, they are used to generate synthetic text data for unlabeled or partially labeled audio that can then support training of machine learning models on other tasks that require (audio, text) pairs, such as text-to-music retrieval and text-to-music generation. This is how some of the latest audio-text music datasets are produced (see Datasets).
The axes of music description#
We can distinguish between different types of music description along two axes:
Abstraction: the abstraction level of the features captured in the description (”what we describe”)
Complexity: the complexity of the description (”how we describe”)
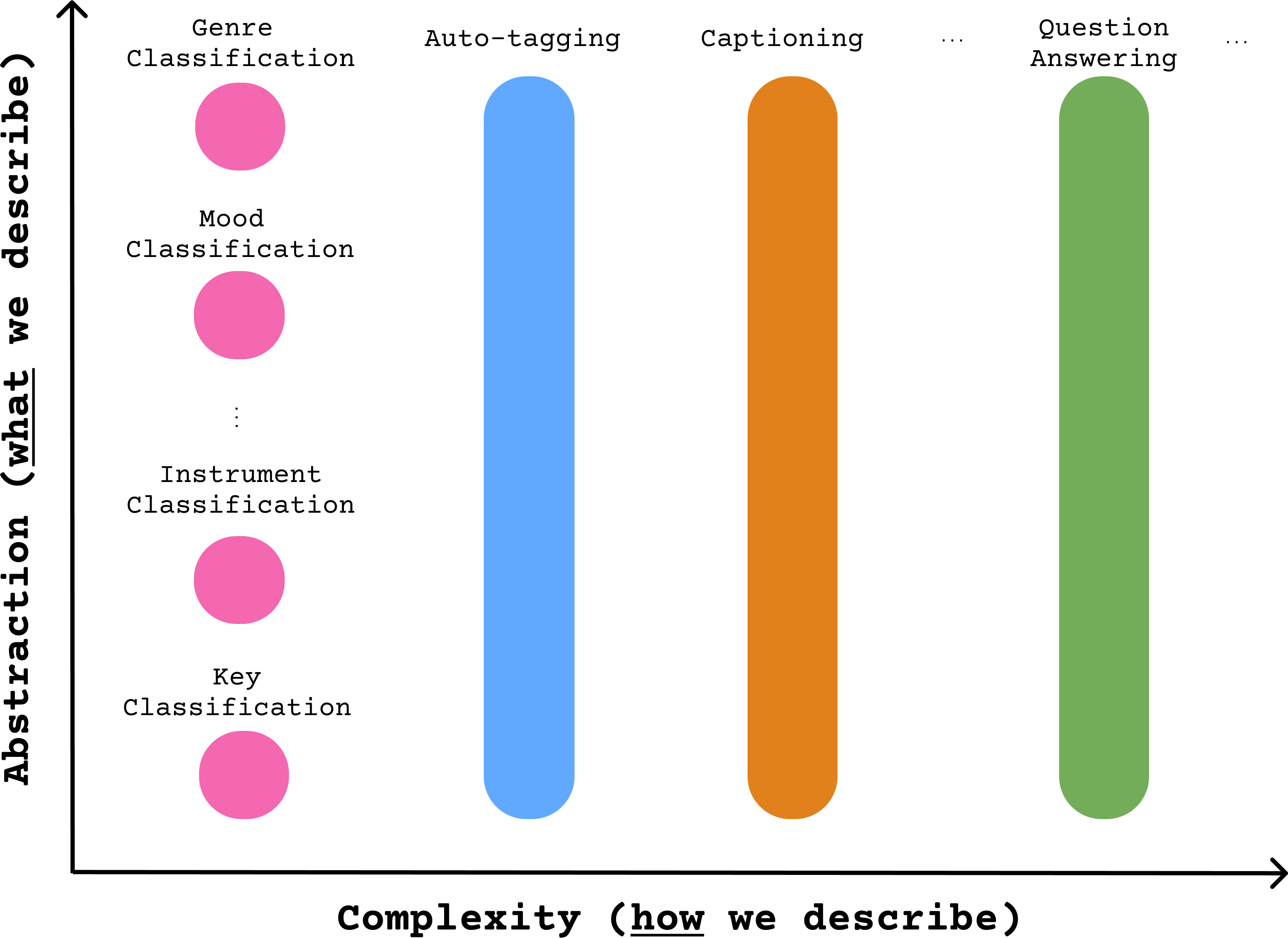
In this tutorial, we’re particularly interested in natural language descriptions, which occupy a higher position on the complexity axis compared to label-based descriptions, and usually span a wide range of abstraction levels. In the following sections, we will review this shift towards more complex description tasks, tracing the evolution of AMU from its classification-based formulation to today’s most common variants.
Overview of this tutorial section#
Overall, this part of the tutorial is structed into 4 section:
In the Tasks section, we describe key music description tasks, highlighting differences between classification-based and language-based tasks, and presenting recent developements in dialogue-based tasks.
In the Models section, we take a look at how this shift towards natural language has gone hand in hand with advancements in deep learning architectures and modelling paradigms. Here, we explain the design of typical music description models, covering architectures, modelling and training paradigms, and respective benefits and shortcomings.
In the Datasets section, we provide useful resources regarding existing data that supports training and evaluation of music description models.
Finally, in the Evaluation section, we talk about how we usually evaluate music description systems today, and discuss some of the main challenges we face.