Tasks#
Music description encompasses several different tasks. Let’s now look at each of these in more detail, going from those that give the simplest form of output (a categorical label) to those that produce more complex, natural language-based outputs. Through this, we also review some of the history of deep learning-based AMU systems.
Music Classification#
Traditionally, music description in MIR has been addressed through supervised classification-based systems that learn to predict a single (or multiple) label(s) based on an audio input, with each label corresponding to a specific, pre-assigned descriptor. For example, we can train classifiers to describe music with respect to categories such as genre [TC02], instrument [PHBD03], mood [KSM+10], and more. Sometimes, multi-label classification (auto-tagging) is instead used to assign tags that cover more than one category, typically encompassing genre, mood, instrument and era [CFSC17] [LN17] [WCS21].
A classifier \(f\) maps the audio to categorical labels chosen from a predefined, often small-size, set of \(K\) labels, \(f: \mathcal{X} \rightarrow \{0, \dots, 1-K\}\). Therefore this type of description is limited in its expressivity, as it cannot adapt to new concepts, or model the relationship between labels.

Note
If you would like to know more about music classification, there is an ISMIR tutorial from 2021 covering this topic.
Music Captioning#
For this reason, in recent years, research on music description has shifted towards incorporating natural language, developing models that map audio inputs to full sentences, \(g: \mathcal{X} \rightarrow \mathcal{V}^*\). In this case, \(\mathcal{V}\) is the vocabulary and \(\mathcal{V}^*\) denotes all possible sequences that can be formed with elements of \(\mathcal{V}\). Enjoying the benefits of natural language, these systems can produce descriptions that are more nuanced, expressive and human-like.
The primary example of language-based music description task is music captioning, in which the goal is to generate natural language outputs describing an audio input:
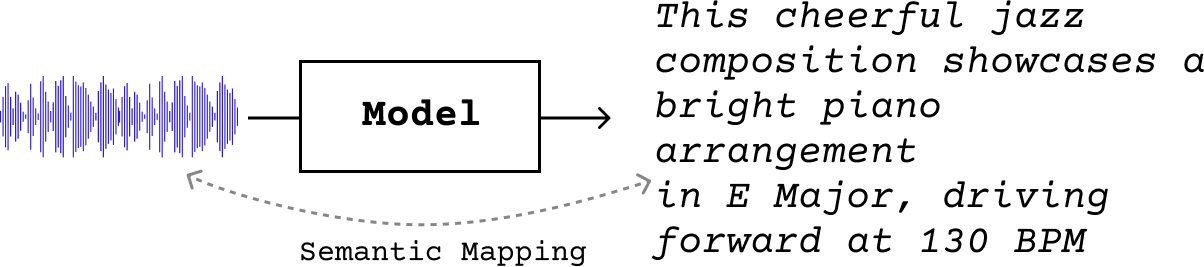
We can think of it as a type of conditional language modelling, where we seek to predict the next token \(y_t\) in a sequence \(Y\) of length \(L\), based not only on prior text tokens \(y_{i<t}\), but also on the audio \(a\):
Types of music captioning#
Music captioning can be performed at the sub-track, track or multi-track level, depending on whether the audio input is a segment from a longer track (typically fixed-sized), a whole variable-length track, or a sequence of multiple tracks (i.e. a playlist). In the latter case, we usually refer to this type of description task by playlist captioning [GHE22]. Instead, when using the terms music captioning we usually mean captioning of either a clip or full track [MBQF21] [MBQF21] [WNN+24]. In a variation of the music captioning task, lyrics may be considered alongside audio as additional input data to base the description on, though this is only explored in one prior study [HHL+23].
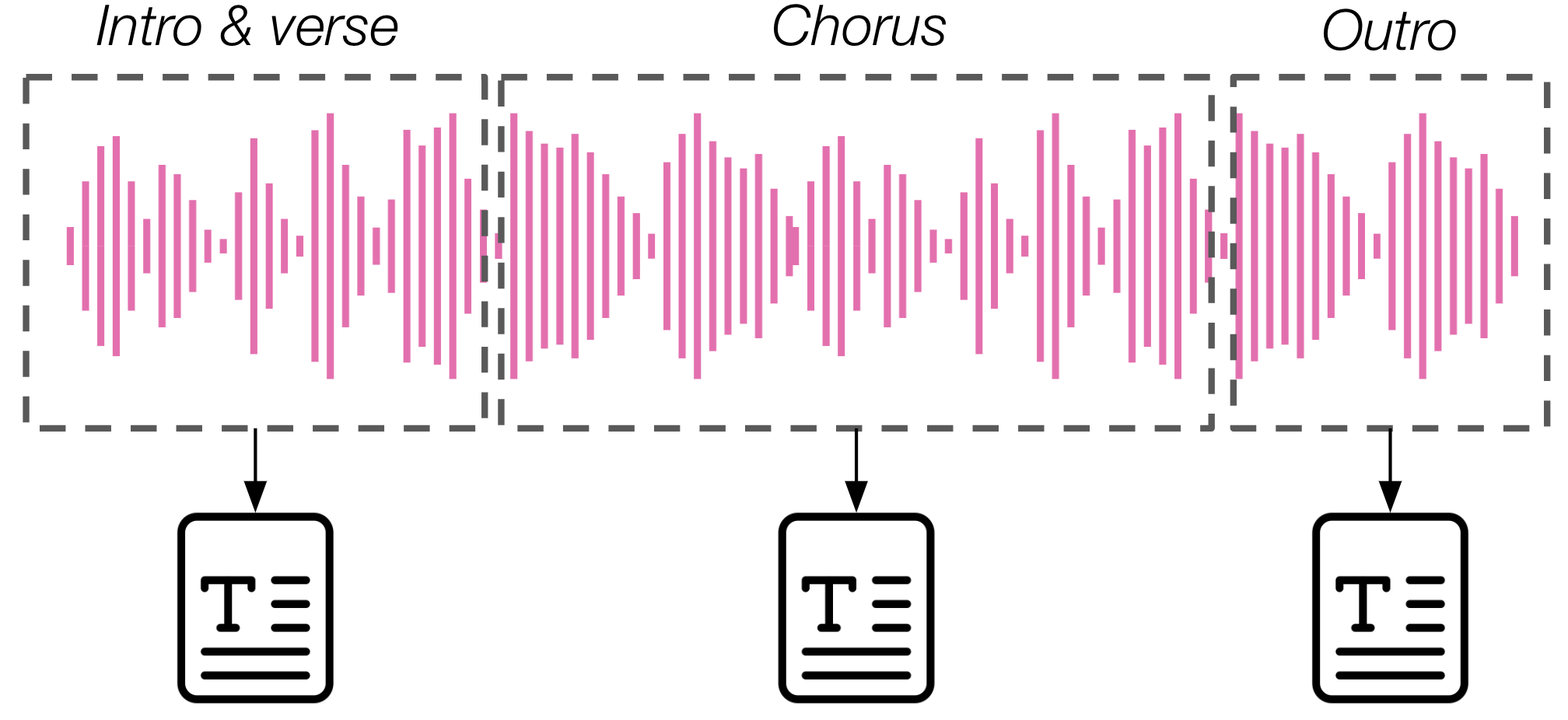
Music captioning is usually focused on describing global characteristics of the content, especially those that emerge at relatively long timescales (~10-30s), such as style and genre. In many cases, this type of caption does not contain references to time-localised events, temporal order, structure, or other types of temporally aware description, and can only convey a high-level, coarse summary of a musical piece. Temporal evolution within audio signals is however a crucial aspect to music. For this reason, more recent variants of this task focus on producing more fine-grained captions that capture structural characteristics [WNN+24].
Music Question Answering#
Hand in hand with more flexible and fine-grained music captioning, recent developments on music description have started going beyond static captioning towards more interactive, dialogue-based description. A primary example of this is music question answering (MQA), where the goal is to obtain a language output that answers a question about a given piece of music:

The MQA task is relatively recent, and the first example we find in the literature comes from Gao et al. (2023) [GLTQ23]. In their work, the authors present a dataset of (music, question, answer) tuples and propose a baseline model trained to predict the answer from the music-question input, alongside items in an aesthetic knowledge base.
However the MQA task has only become more established with the development of multimodal AR models such as LLark [GDSB23], MusiLingo [DML+24] and MuLLaMa, which we discuss in more detail in the Models section.
Conversational Music Description#
Finally, an even more generalised form of music description can be achieved through conversational music description or music dialogue generation, in which the goal is to obtain suitable language outputs in response to both language inputs and accompanying music audio, in a multi-turn fashion:
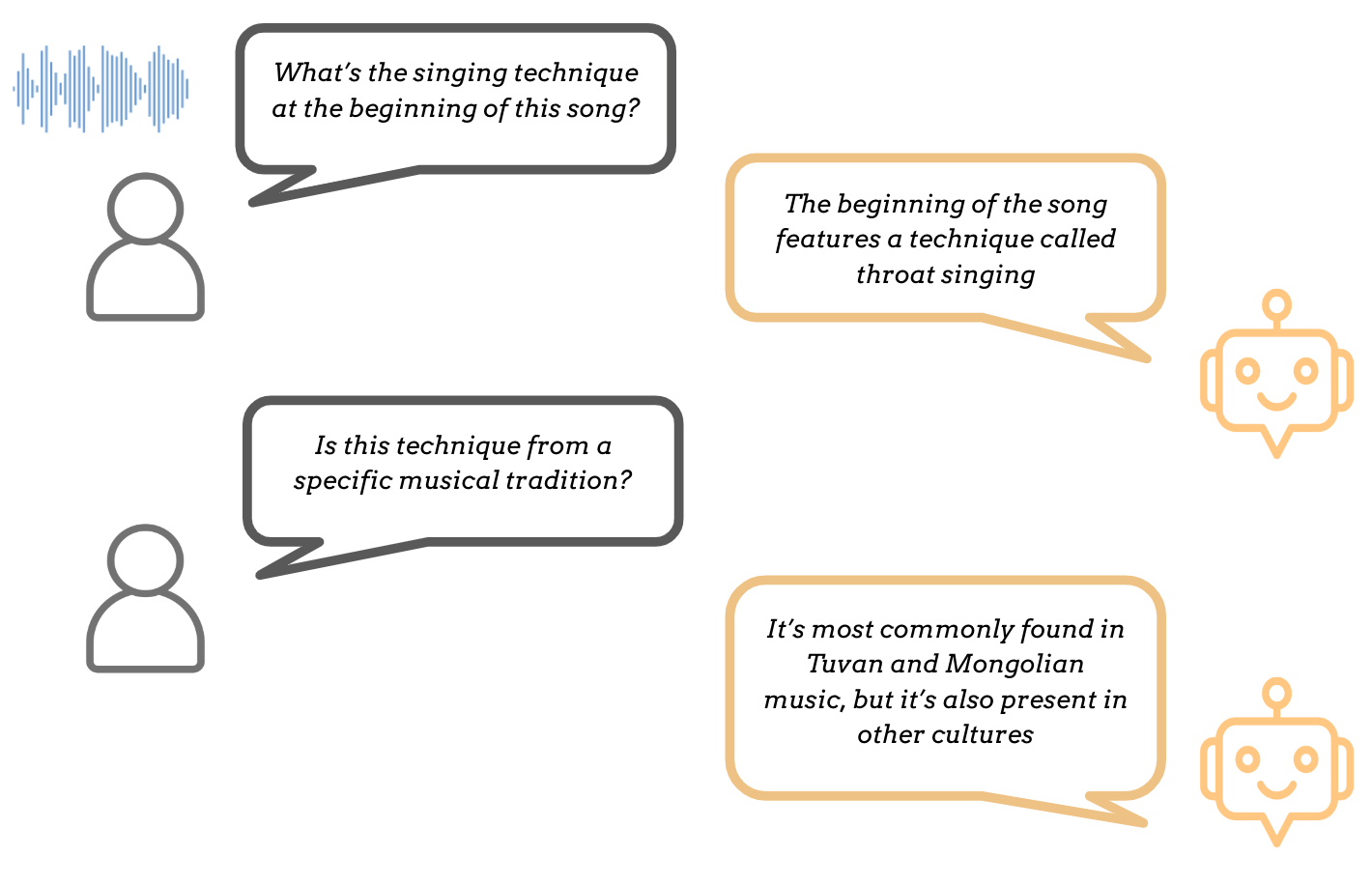
A key difference between dialogue-based description and one-off captioning is that, instead of an audio --> text mapping, we are now dealing with an (audio, text) --> text mapping. This is reflected in the different model designs typically considered for these tasks (see Models). Differently from simple MQA, in music dialogue generation, responses are expected to be based on the entire dialogue history instead of only considering the current input.
In terms of real-world applications, the advantages of dialogue-based description are clear: instead of being constrained to a one-shot caption or answer, it allows users to provide text inputs to further instruct the model on what kind of information should be included, or how the text output itself should be structured. In short, these tasks make for a much more flexible approach which better reflects real-world use. One drawback is that they are harder to evaluate (see Evaluation)!
References#
Keunwoo Choi, György Fazekas, Mark Sandler, and Kyunghyun Cho. Convolutional recurrent neural networks for music classification. In 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), volume, 2392–2396. 2017. doi:10.1109/ICASSP.2017.7952585.
Zihao Deng, Yinghao Ma, Yudong Liu, Rongchen Guo, Ge Zhang, Wenhu Chen, Wenhao Huang, and Emmanouil Benetos. MusiLingo: Bridging Music and Text with Pre-trained Language Models for Music Captioning and Query Response. In Kevin Duh, Helena Gomez, and Steven Bethard, editors, Findings of the Association for Computational Linguistics: NAACL 2024, 3643–3655. Mexico City, Mexico, June 2024. Association for Computational Linguistics. URL: https://aclanthology.org/2024.findings-naacl.231 (visited on 2024-07-04).
Giovanni Gabbolini, Romain Hennequin, and Elena Epure. Data-efficient playlist captioning with musical and linguistic knowledge. In Yoav Goldberg, Zornitsa Kozareva, and Yue Zhang, editors, Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, 11401–11415. Abu Dhabi, United Arab Emirates, December 2022. Association for Computational Linguistics. URL: https://aclanthology.org/2022.emnlp-main.784, doi:10.18653/v1/2022.emnlp-main.784.
Wenhao Gao, Xiaobing Li, Yun Tie, and Lin Qi. Music Question Answering Based on Aesthetic Experience. In 2023 International Joint Conference on Neural Networks (IJCNN), 01–06. June 2023. ISSN: 2161-4407. URL: https://ieeexplore.ieee.org/abstract/document/10191775 (visited on 2024-03-01), doi:10.1109/IJCNN54540.2023.10191775.
Josh Gardner, Simon Durand, Daniel Stoller, and Rachel M Bittner. Llark: a multimodal foundation model for music. arXiv preprint arXiv:2310.07160, 2023.
Zihao He, Weituo Hao, Wei-Tsung Lu, Changyou Chen, Kristina Lerman, and Xuchen Song. Alcap: alignment-augmented music captioner. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, 16501–16512. 2023.
Youngmoo E Kim, Erik M Schmidt, Raymond Migneco, Brandon G Morton, Patrick Richardson, Jeffrey Scott, Jacquelin A Speck, and Douglas Turnbull. Music emotion recognition: a state of the art review. In Proc. ismir, volume 86, 937–952. 2010.
Jongpil Lee and Juhan Nam. Multi-level and multi-scale feature aggregation using pretrained convolutional neural networks for music auto-tagging. IEEE Signal Processing Letters, 24(8):1208–1212, 2017. doi:10.1109/LSP.2017.2713830.
Ilaria Manco, Emmanouil Benetos, Elio Quinton, and György Fazekas. Muscaps: generating captions for music audio. In 2021 International Joint Conference on Neural Networks (IJCNN), 1–8. IEEE, 2021.
Geoffroy Peeters Perfecto Herrera-Boyer and Shlomo Dubnov. Automatic classification of musical instrument sounds. Journal of New Music Research, 32(1):3–21, 2003. doi:10.1076/jnmr.32.1.3.16798.
G. Tzanetakis and P. Cook. Musical genre classification of audio signals. IEEE Transactions on Speech and Audio Processing, 10(5):293–302, 2002. doi:10.1109/TSA.2002.800560.
Minz Won, Keunwoo Choi, and Xavier Serra. Semi-supervised music tagging transformer. In Proc. of International Society for Music Information Retrieval. 2021.