Connecting Music Audio and Natural Language#
Welcome to the online supplement for the tutorial on “Connecting Music Audio and Natural Language,” presented at the 25th International Society for Music Information Retrieval (ISMIR) Conference, from November 10–14, 2024 in San Francisco, CA, USA. This web book contains all the content presented during the tutorial, including code examples, references, and additional materials that delve deeper into the topics covered.
Motivation & Aims#
Language serves as an efficient interface for communication between humans as well as between humans and machines. With the recent advancements in deep learning-based pretrained language models the understanding, search, and creation of music are now capable of catering to user preferences with diversity and precision. This tutorial is motivated by the rapid advancements in machine learning techniques, particularly in the domain of language models, and their burgeoning applications in the field of Music Information Retrieval (MIR). The remarkable capability of language models to understand and generate human-like text has paved the way for innovative methodologies in music description, retrieval, and generation, heralding a new era in how we interact with music through technology.
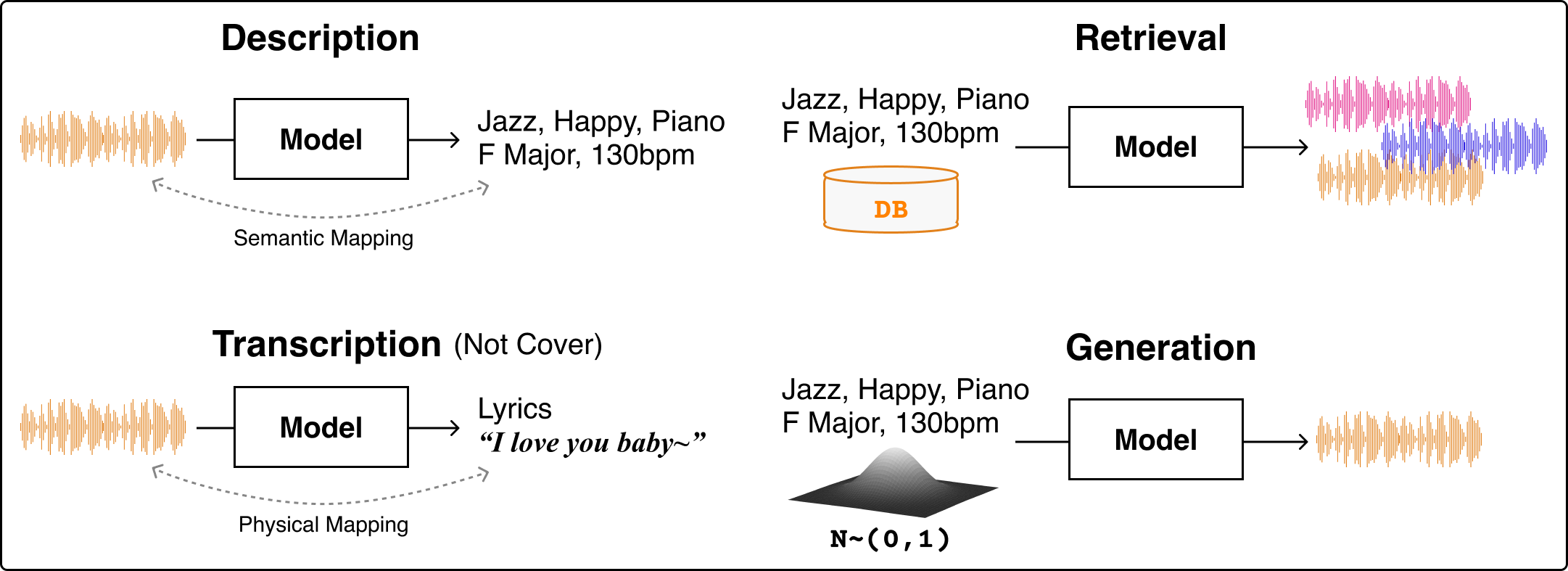
Fig. 1 Overview of frameworks with connections between music and language. In this tutorial, we focus on explaining description, retrieval, and generation. However, we do not include transcription in our discussion.#
We firmly believe that the MIR community will derive substantial benefits from this tutorial. Our discussion will not only highlight why the multimodal approach of combining music and language models signifies a significant departure from conventional task-specific models but will also provide a detailed survey of the latest advancements, unresolved challenges, and potential future developments in the field. In parallel, we aim to establish a solid foundation to encourage the participation of emerging researchers in the domain of music-language research, by offering comprehensive access to relevant datasets, evaluation methodologies, and coding best practices, thereby fostering an inclusive and innovative research environment.
Getting Started#
This web book consists of a series of Jupyter notebooks, which can be explored statically on this page. To run the notebooks yourself, you will need to clone the Git repository:
git clone https://github.com/mulab-mir/music-language-tutorial/ && cd music-language-tutorial
conda create --name p310 python==3.10 && conda activate python
Next, you should install the dependencies:
pip install -r requirements.txt
And finally, you can launch the Jupyter notebook server:
jupyter notebook
About the Authors#

SeungHeon Doh is a Ph.D. Candidate at the Music and Audio Computing Lab, KAIST, under the guidance of Juhan Nam. His research focuses on conversational music description, retrieval, and generation. SeungHeon has published papers related to music & language models at ISMIR, ICASSP and IEEE TASLP. He aims to enable machines to comprehend diverse modalities during conversations, thus facilitating the understanding and discovery of music through dialogue. SeungHeon has interned at Chartmetric, NaverCorp, and ByteDance, applying his expertise in real-world scenarios.

Ilaria Manco is a PhD student at the Centre for Doctoral Training in Artificial Intelligence and Music (Queen Mary University of London), under the supervision of Emmanouil Benetos, George Fazekas, and Elio Quinton (UMG). Her research focuses on multimodal deep learning for music information retrieval, with an emphasis on audio-and-language models for music understanding. Her contributions to the field have been published at ISMIR and ICASSP and include the first captioning model for music and representation learning approaches to connect music and language. Previously, she was a research intern at Google DeepMind, Adobe and Sony and obtained an MSci in physics from Imperial College London.

Zachary Novack is a Ph.D. Student at the University of California – San Diego, where he is advised by Julian McAuley and Taylor Berg-Kirkpatrick. His research is primarily aimed at efficient and controllable music and audio generation. Specifically, Zachary seeks to build generative music models that allow for flexible musically-salient controls, while accelerating such models so that they can be used in practical production workflows. Zachary has interned at Stability AI and Adobe Research, contributing such works as DITTO-(1/2) and Presto!. Outside of academics, Zachary is passionate about music education and teaches percussion in the southern California area.

Jong Wook Kim is a Member of Technical Staff at OpenAI where he has worked on multimodal deep learning models such as Jukebox, CLIP, Whisper, and GPT-4. He has published at ICML, CVPR, ICASSP, IEEE SPM, and ISMIR, and he co-presented a tutorial on self-supervised learning at the NeurIPS 2021 conference. He completed a Ph.D. in Music Technology at New York University with a thesis focusing on automatic music transcription, and he has an M.S. in Computer Science and Engineering from the University of Michigan, Ann Arbor. He interned at Pandora and Spotify during the Ph.D. study, and he worked as a software engineer at NCSOFT and Kakao.

Ke Chen is a Ph.D. Candidate in the department of computer science and engineering at University of California San Diego. His research interests span across the music and audio representation learning, with a particular focus on its downstream applications of music generative AI, audio source separation, multi-modal learning, and music information retrieval. He has interned at Apple, Mitsubishi, Tencent, Bytedance, and Adobe, to further explore his research directions. During his PhD study, Ke Chen has published more than 20 papers in top-tier conferences in the fields of artificial intelligence, signal processing, and music, such as AAAI, ICASSP, and ISMIR. Outside of academics, he indulges in various music-related activities, including piano performance, singing, and music composition.