Code Practice#
You can find this notebook on Colab at this link.
Introduction#
In this code example, we will build a simple music captioning model.
As we’ve seen in the tutorial, music captioning is the task of processing music audio and producing natural language that describes its content.
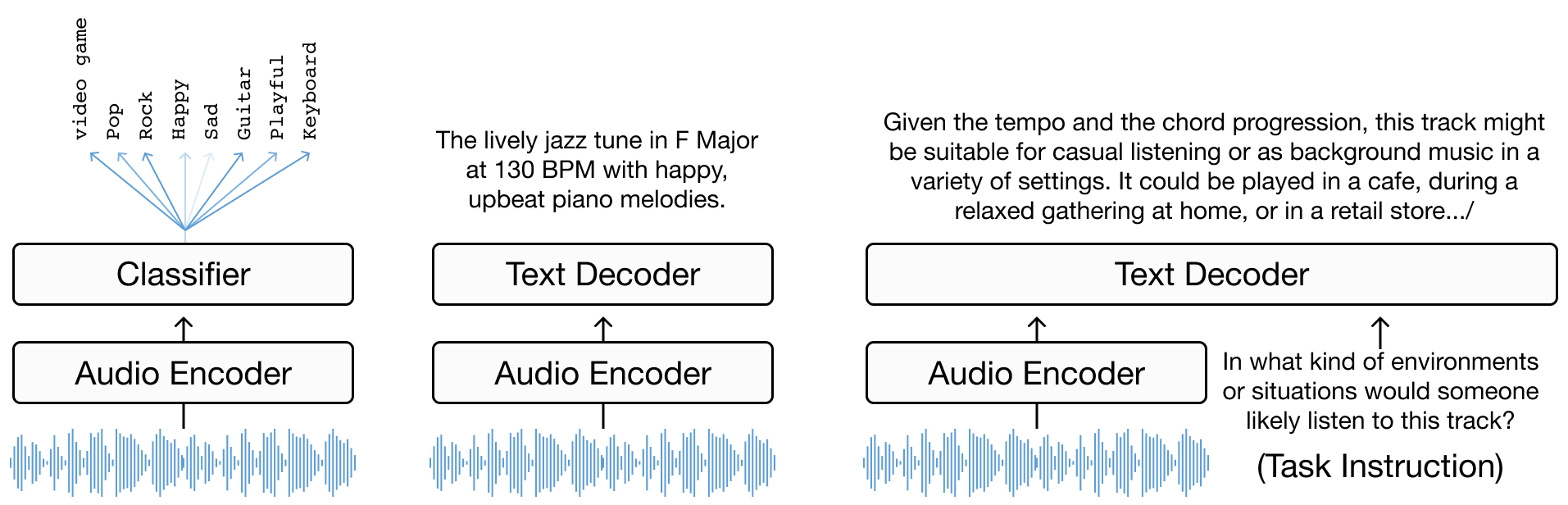
The task can be framed as language modelling conditioned on music signals, and we have seen that there are different modelling paradigms through which we can achieve this. Encoder-decoder models, in particular, are a common framework used in music captioning (as well as other types of media captioning). As the name suggests, this type of model simply consists of an encoder which produces representations of the input audio and a decoder which “translates” these representations into natural language.
What we will build#
Now we put what we’ve learnt so far into practice by building and training our own encoder-decoder model for music captioning. In order to make training feasible within a short(ish) session, we use a small dataset and leverage pre-trained audio encoding and text decoding modules. But the overall principle and design is not dissimilar from more sophisticated models. More specifically, we use:
MusicFM as our audio encoder: Minz et al. A Foundation Model for Music Informatics
GPT2 as our text decoder: Radford et al. Language Models are Unsupervised Multitask Learners
Prerequisites#
Basic Python knowledge
Familiarity with deep learning concepts
Google Colab account (free!)
We build the model with PyTorch and use HuggingFace Datasets to quickly set up the data, but the code should be simple enough to follow even if you’re not too familiar with these tools.
Let’s Get Started! 🚀#
Step 1: Setting up our environment#
First, let’s set up our Google Colab environment. Create a new notebook and make sure you’ve got that GPU runtime enabled.
import torch
print("GPU Available:", torch.cuda.is_available())
print("GPU Device Name:", torch.cuda.get_device_name(0) if torch.cuda.is_available() else "No GPU")
GPU Available: False
GPU Device Name: No GPU
Step 2: Loading the data 📊#
We’ll be using a subset of the LP-MusicCaps-MTT dataset. This is great for us as as it’s not too large (3k training samples, 300 test samples) and includes 10-second clips of CC-licensed music.
%%capture
!pip install datasets transformers
import torchaudio
import torch.nn as nn
from tqdm.notebook import tqdm
from transformers import AutoModel, Wav2Vec2FeatureExtractor, GPT2LMHeadModel, GPT2Tokenizer
from datasets import load_dataset
from IPython.display import Audio
dataset = load_dataset("mulab-mir/lp-music-caps-magnatagatune-3k", split="train")
---------------------------------------------------------------------------
ModuleNotFoundError Traceback (most recent call last)
Cell In[2], line 2
1 get_ipython().system('pip install datasets transformers')
----> 2 import torchaudio
3 import torch.nn as nn
4 from tqdm.notebook import tqdm
ModuleNotFoundError: No module named 'torchaudio'
print("Original Magnatagatune Tags: ", dataset[10]['tags'])
print("-"*10)
print("LP-MusicCaps Captions: ")
print("\n".join(dataset[10]['texts']))
Audio(dataset[10]['audio']["array"], rate=22050)
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In[3], line 1
----> 1 print("Original Magnatagatune Tags: ", dataset[10]['tags'])
2 print("-"*10)
3 print("LP-MusicCaps Captions: ")
NameError: name 'dataset' is not defined
Step 3: Creating our dataset class 🎨#
In order to pass our training (music, caption) pairs to the model, let’s create a dataset class to process the data and load it in the correct format.
import torch
import random
from torch.utils.data import Dataset
class MusicTextDataset(Dataset):
def __init__(self, split="train"):
self.data = load_dataset("mulab-mir/lp-music-caps-magnatagatune-3k", split=split)
musicfm_embeds = load_dataset("mulab-mir/lp-music-caps-magnatagatune-3k-musicfm-embedding", split=split)
self.track2embs = {i["track_id"]:i["embedding"] for i in musicfm_embeds}
def __len__(self):
return len(self.data)
def __getitem__(self, index: int):
item = self.data[index]
text = random.choice(item['texts'])
embeds = torch.tensor(self.track2embs[item['track_id']]).unsqueeze(0)
return {
"text": text,
"embeds": embeds
}
train_dataset = MusicTextDataset(split="train")
test_dataset = MusicTextDataset(split="test")
tr_dataloader = torch.utils.data.DataLoader(train_dataset, batch_size=32, shuffle=True, drop_last=True)
te_dataloader = torch.utils.data.DataLoader(test_dataset, batch_size=32, shuffle=False, drop_last=True)
for item in test_dataset:
print(item)
break
{'text': 'A powerful female Indian vocalist captivates listeners with her mesmerizing rock singing, infusing her foreign roots into an electrifying blend of contemporary sounds, delivering a captivating performance that evades the realm of opera.', 'embeds': tensor([[ 0.5781, -0.0933, -0.1426, ..., 0.1165, -0.2231, -1.4524]])}
Step 4: Building and training our model 🏗️#
Now we move to the model part, and start by writing the code for the model architecture. This consists of:
MusicFM for music understanding (audio encoder)
GPT-2 for generating captions (text decoder)
A mapping module to project audio embeddings extracted through MusicFM to the input space of our text decoder. These are then passed to GPT2 as a prefix
class MusicCaptioningModel(torch.nn.Module):
def __init__(self):
super().__init__()
# Initialize the GPT-2 model and tokenizer
self.text_model = GPT2LMHeadModel.from_pretrained("gpt2")
self.text_tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
if self.text_tokenizer.pad_token is None:
self.text_tokenizer.pad_token = "[PAD]"
self.text_tokenizer.pad_token_id = self.text_tokenizer.convert_tokens_to_ids("[PAD]")
self.text_model.resize_token_embeddings(len(self.text_tokenizer))
self.text_embedding_dim = self.text_model.transformer.wte.weight.shape[1]
self.audio_embedding_dim = 1024 # Hard Coding MusicFM dim
self.a2t_projection = nn.Sequential(
nn.Linear(self.audio_embedding_dim, self.text_embedding_dim),
nn.ReLU(),
nn.Linear(self.text_embedding_dim, self.text_embedding_dim)
)
# self.freeze_backbone_model()
@property
def device(self):
return list(self.parameters())[0].device
@property
def dtype(self):
return list(self.parameters())[0].dtype
def freeze_backbone_model(self):
for param in self.text_model.parameters():
param.requires_grad = False
self.text_model.eval()
def forward(self, batch):
prefix = batch['embeds'].to(self.device)
prefix_length = prefix.shape[1]
embedding_prefix = self.a2t_projection(prefix)
inputs = self.text_tokenizer(batch['text'],
padding='longest',
truncation=True,
max_length=128,
add_special_tokens=True,
return_tensors="pt")
tokens = inputs["input_ids"].to(self.device)
mask = inputs['attention_mask'].to(self.device)
bos_token_id = self.text_tokenizer.bos_token_id
bos_embedding = self.text_model.transformer.wte(torch.tensor([bos_token_id], device=self.device)).expand(embedding_prefix.shape[0], 1, -1)
embedding_text = self.text_model.transformer.wte(tokens)
embedding_cat = torch.cat((embedding_prefix, bos_embedding, embedding_text), dim=1)
# Update attention mask to include prefix
if mask is not None:
prefix_mask = torch.ones((mask.shape[0], prefix_length + 1), dtype=mask.dtype, device=mask.device)
mask = torch.cat((prefix_mask, mask), dim=1)
outputs = self.text_model(inputs_embeds=embedding_cat, attention_mask=mask)
logits = outputs.logits[:, prefix_length:-1, :]
labels = tokens.clone()
labels = torch.where(labels == self.text_tokenizer.pad_token_id, -100, labels)
loss = torch.nn.functional.cross_entropy(
logits.contiguous().reshape(-1, logits.size(-1)),
labels.contiguous().reshape(-1),
ignore_index=-100
)
return loss
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = MusicCaptioningModel()
model.to(device)
train_parmas = sum(p.numel() for p in model.parameters() if p.requires_grad)
freeze_parmas = sum(p.numel() for p in model.parameters() if not p.requires_grad)
print(f"training model with: train_parmas {train_parmas} params, and {freeze_parmas} freeze parmas")
/usr/local/lib/python3.10/dist-packages/transformers/tokenization_utils_base.py:1601: FutureWarning: `clean_up_tokenization_spaces` was not set. It will be set to `True` by default. This behavior will be depracted in transformers v4.45, and will be then set to `False` by default. For more details check this issue: https://github.com/huggingface/transformers/issues/31884
warnings.warn(
training model with: train_parmas 125817600 params, and 0 freeze parmas
def train(model, dataloader, optimizer):
model.train()
total_loss = 0
pbar = tqdm(dataloader, desc=f'TRAIN Epoch {epoch:02}') # progress bar
for batch in pbar:
optimizer.zero_grad()
loss = model(batch)
loss.backward()
optimizer.step()
total_loss += loss.item()
epoch_loss = total_loss / len(dataloader)
return epoch_loss
def test(model, dataloader):
model.eval()
total_loss = 0
pbar = tqdm(dataloader, desc=f'TEST') # progress bar
for batch in pbar:
with torch.no_grad():
loss = model(batch)
total_loss += loss.item()
epoch_loss = total_loss / len(dataloader)
return epoch_loss
NUM_EPOCHS = 10
# Define optimizer and loss function
optimizer = torch.optim.AdamW(model.parameters(), lr=1e-4)
criterion = torch.nn.CrossEntropyLoss()
for epoch in range(NUM_EPOCHS):
train_loss = train(model, tr_dataloader, optimizer)
valid_loss = test(model, te_dataloader)
print("[Epoch %d/%d] [Train Loss: %.4f] [Valid Loss: %.4f]" % (epoch + 1, NUM_EPOCHS, train_loss, valid_loss))
[Epoch 1/10] [Train Loss: 2.6262] [Valid Loss: 2.3479]
[Epoch 2/10] [Train Loss: 2.3122] [Valid Loss: 2.2358]
[Epoch 3/10] [Train Loss: 2.1869] [Valid Loss: 2.1874]
[Epoch 4/10] [Train Loss: 2.1267] [Valid Loss: 2.1481]
[Epoch 5/10] [Train Loss: 2.0702] [Valid Loss: 2.1446]
[Epoch 6/10] [Train Loss: 2.0092] [Valid Loss: 2.0984]
[Epoch 7/10] [Train Loss: 1.9748] [Valid Loss: 2.0577]
[Epoch 8/10] [Train Loss: 1.9315] [Valid Loss: 2.0791]
[Epoch 9/10] [Train Loss: 1.9090] [Valid Loss: 2.0583]
[Epoch 10/10] [Train Loss: 1.8630] [Valid Loss: 2.0586]
Results 📈#
item = test_dataset[39]
model.eval()
with torch.no_grad():
prefix = torch.tensor(item['embeds']).unsqueeze(0)
prefix_projections = model.a2t_projection(prefix.to(model.device))
input_ids = torch.tensor([[model.text_tokenizer.bos_token_id]]).to(model.device)
embedding_text = model.text_model.transformer.wte(input_ids)
embedding_cat = torch.cat((prefix_projections, embedding_text), dim=1)
outputs = model.text_model.generate(
inputs_embeds=embedding_cat,
max_length= 128,
num_return_sequences=1,
repetition_penalty=1.1,
do_sample=True,
top_k=50,
top_p=0.90,
temperature=.1,
eos_token_id=model.text_tokenizer.eos_token_id,
pad_token_id=model.text_tokenizer.pad_token_id
)
generated_text = model.text_tokenizer.decode(outputs[0], skip_special_tokens=True)
<ipython-input-14-0da8e798b168>:4: UserWarning: To copy construct from a tensor, it is recommended to use sourceTensor.clone().detach() or sourceTensor.clone().detach().requires_grad_(True), rather than torch.tensor(sourceTensor).
prefix = torch.tensor(item['embeds']).unsqueeze(0)
This classical opera piece features a powerful female vocal accompanied by the enchanting sound of violins and strings. The operatic performance is highlighted by the beautiful violin solos and the grandiose orchestra, creating an orchestral masterpiece that will transport you to another world. With its timeless beauty and intricate melodies, this song is sure to captivate any listener. Its popularity has skyrocketed with fans of classic music and women's voices, making it a must-listen for anyone who appreciates the power of female vocals in opera. This womanly tune is truly breathtaking! Let her voice take center stage as she belts out
import textwrap
width = 50
gt = "\n".join(textwrap.wrap(item['text'], width=width))
generated = "\n".join(textwrap.wrap(generated_text, width=width))
print(f"Ground Truth:\n{gt}\n")
print(f"Generated:\n{generated}")
Ground Truth:
The soaring soprano notes of a talented female
opera singer dominate the stage, conveying both
power and delicate emotion in equal measure.
Generated:
This classical opera piece features a powerful
female vocal accompanied by the enchanting sound
of violins and strings. The operatic performance
is highlighted by the beautiful violin solos and
the grandiose orchestra, creating an orchestral
masterpiece that will transport you to another
world. With its timeless beauty and intricate
melodies, this song is sure to captivate any
listener. Its popularity has skyrocketed with fans
of classic music and women's voices, making it a
must-listen for anyone who appreciates the power
of female vocals in opera. This womanly tune is
truly breathtaking! Let her voice take center
stage as she belts out
Conclusion 🎉#
We now have a first version of our music captioning model! Next, we can think about how to improve it.
First, a few standard things to try:
Try different architectures and/or pre-trained encoders (e.g. MERT)
Experiment with larger datasets (see the datasets section in the tutorial book for some inspiration)
A few more things you might want to consider:
What happens if we freeze the text decoder and only train the mapping module?
How can we improve conditioning on music signals?
How can we ensure audio representations passed to the text decoder preserve temporal information?
Music signals have defining characteristics that distinguish them from other types of audio signals. Can we incorporate this domain knolwedge to improve conditioning? Or better yet, can we design components of our captioning model so that they have capacity to learn these characteristics?
And finally, play around with captioning your own music! For this, you’ll need to extract MusicFM embeddings first.