Models#
Deep learning models for music description via natural language typically fit into one of two designs:
Encoder-decoder models
Multimodal AR models, most often in the form of adapted LLMs
In Table 1 we give an overview of music description models from 2016 to today. * denotes taks that don’t fall under the music description umbrella but are still addressed by the model.
Model |
Type |
Task(s) |
Weights |
Training dataset |
|---|---|---|---|---|
Choi et al. [MBQF21] |
Encoder-decoder |
Captioning (playlist) |
❌ |
Private data |
MusCaps [MBQF21] |
Encoder-decoder |
Captioning, retrieval* |
❌ |
Private data |
PlayNTell [GHE22] |
Encoder-decoder |
Captioning (playlist) |
✅ link |
PlayNTell |
LP-MusicCaps [MBQF21] |
Encoder-decoder |
Captioning |
✅ link |
LP-MusicCaps |
ALCAP [HHL+23] |
Encoder-decoder |
Captioning |
❌ |
Song Interpretation Dataset, NetEase Cloud Music Review Dataset |
BLAP [LPPW24] |
Adapted LLM |
Captioning |
✅ link |
Shutterstock (31k clips) |
LLark [GDSB23] |
Adapted LLM |
Captioning, MQA |
❌ |
MusicCaps, YouTube8M-MusicTextClips, MusicNet, FMA, MTG-Jamendo, MagnaTagATune |
MU-LLaMA [LHSS24] |
Adapted LLM |
Captioning, MQA |
✅ link |
MusicQA |
MusiLingo [DML+24] |
Adapted LLM |
Captioning, MQA |
✅ link |
MusicInstruct |
M2UGen[HLSS23] |
Adapted LLM |
Captioning, MQA, music generation |
✅ link |
MUCaps, MUEdit |
OpenMU [ZZM+24] |
Adapted LLM |
Captioning, MQA |
✅ link |
MusicCaps, YouTube8M-MusicTextClips, MusicNet, FMA, MTG-Jamendo, MagnaTagATune |
FUTGA [WNN+24] |
Adapted LLM |
Captioning (fine-grained) |
✅ link |
FUTGA |
Encoder-Decoder Models#
This is the modelling framework of the earliest DL music captioning models. Encoder-decoder models first emerged in the context of sequence-to-sequence tasks (e.g. machine translation). It is easy to see many tasks can be cast as sequence-to-sequence, so encoder-decoder models found wide use in image captioning first, and audio captioning shortly after, including music.
As the name suggests, models of this type are composed of two main modules: an encoder and a decoder. Although there are several variations, in the simplest design of these models, the encoder is resposible for processing the input sequence (i.e. audio input) into an intermediate representation (the context \(c\))
and the decoder then “unrolls” this representation into a target sequence (e.g. text describing the audio input), typically computing the probability distribution over possible tokens at each step in the sequence, conditioned on the context \(c\):
Architectures#
When it comes to the design of the encoder and decoder components, the general philosophy is to adopt state-of-the-art architectures for the respective modalities, balancing our requirements around possible domain-specific restrictions (e.g. the need to capture features at different timescales in music signals), with the computational and data budget we have at our disposal. This is to say that there are many possible designs for encoder-decoder music captioners in theory, but most follow standard choices. Let’s review some below.
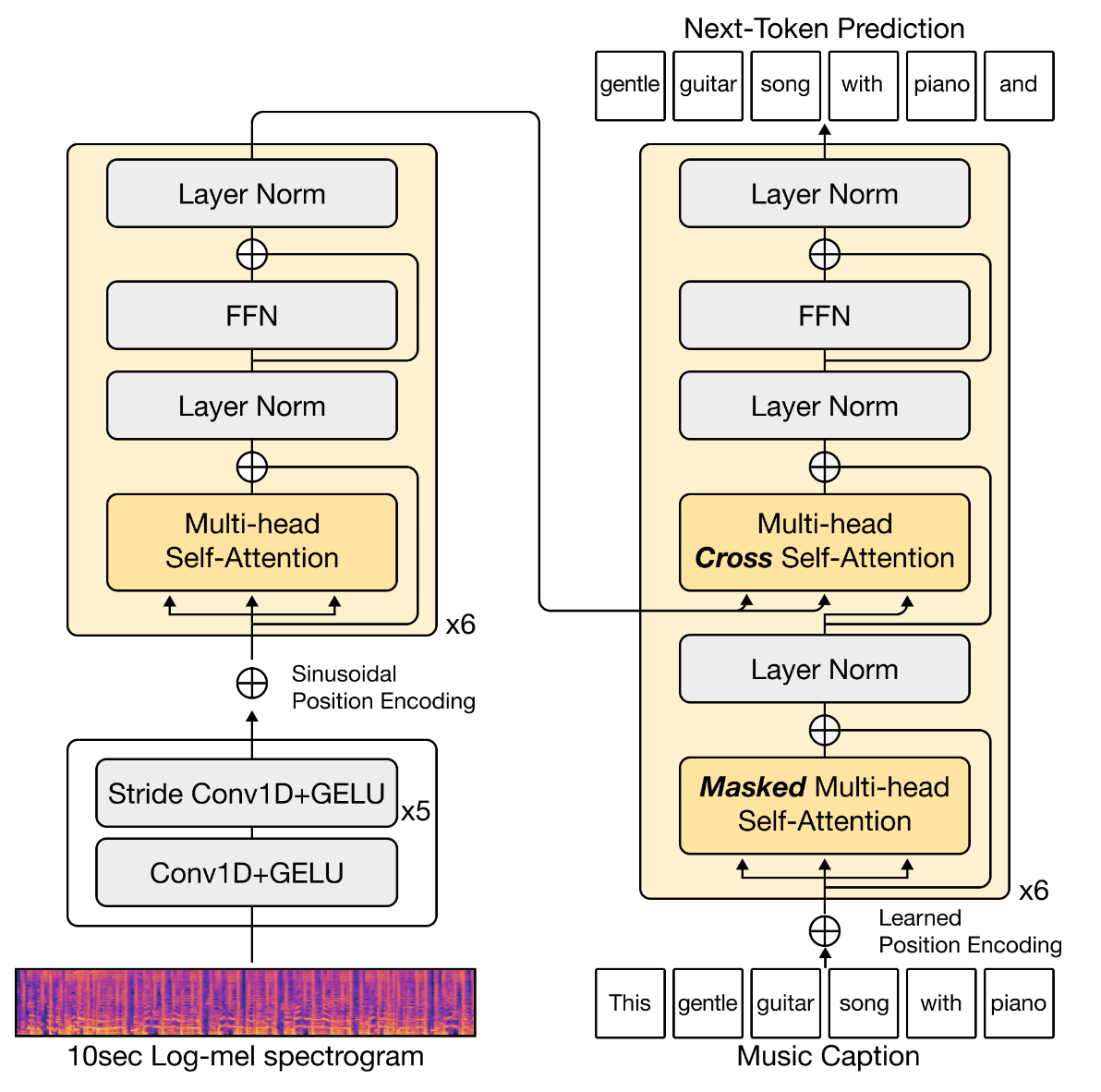
The first example of encoder-decoder model for music description appeared in work by Choi et al. [CFS16]. While this did not yet produce well-formed sentences, a later model by Manco et al., MusCaps [MBQF21], consolidated the use of a similar architecture for track-level music captioning. These early iterations of encoder-decoder music captioners employed CNN-based audio encoders alongside RNN-based language decoders. More recent iterations of this framework typically make use of a Transformer-based language decoder (e.g. based on Transformer decoders such as GPT-2 [GHE22] or BART [DCLN23]), alongside CNNs [GHE22] or Transformer audio encoders [SCDBK24], and sometimes a hybrid of both [DCLN23].
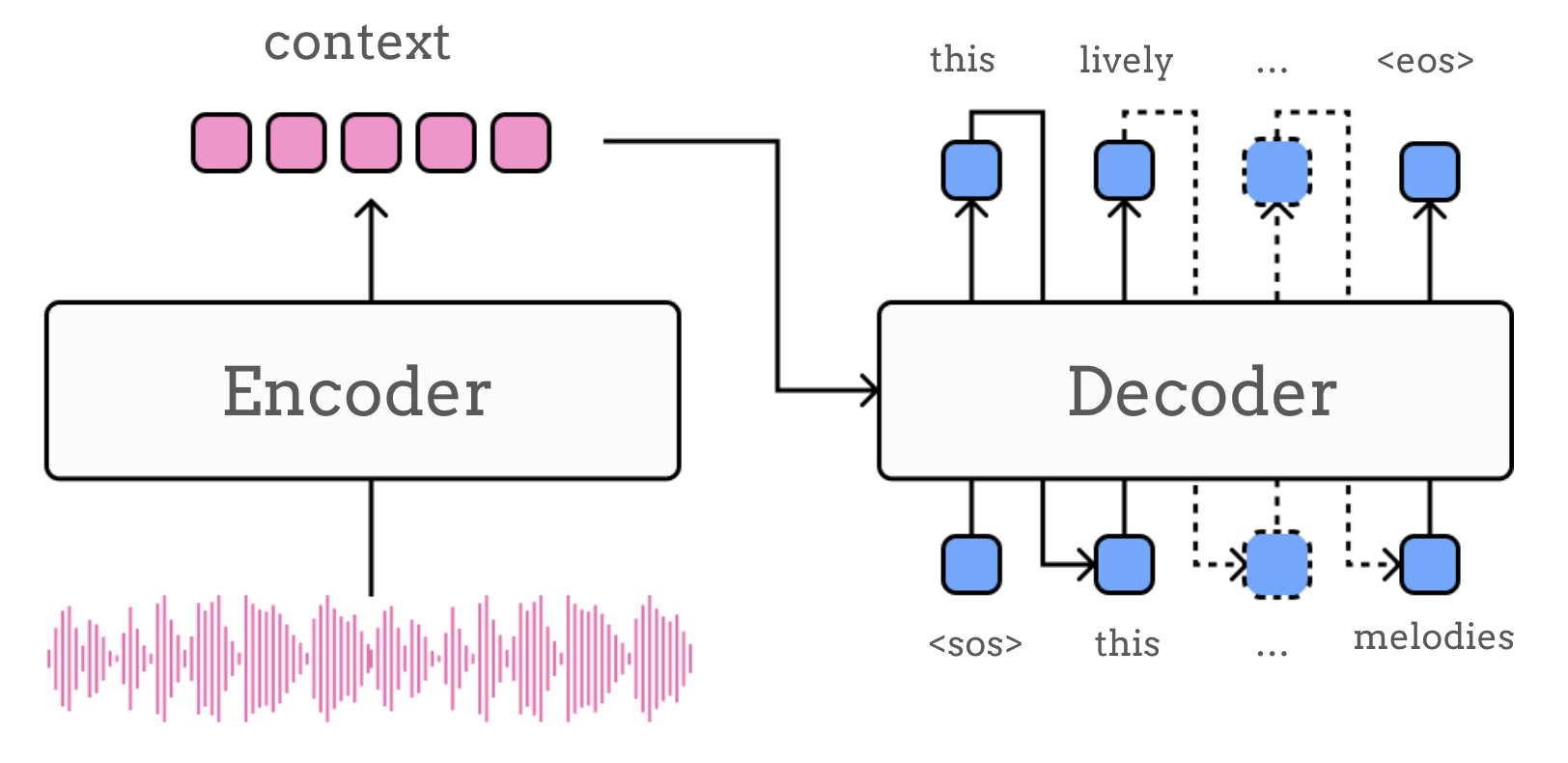
Conditioning and Fusion#
Now that we’ve discussed how to choose our encoder and our decoder, how do we connect the two in order to join the two modalities we are translating between? Of course there are standard ways to pass the encoder output to the decoder, but since we are dealing with different modalities, this requires a bit more care than usual. The type of mechanism employed to condition language generation on the audio input is in fact one of the key differentiating aspects between different encoder-decoder models. In practice, this choice is tied to the network architecture of our encoder and decoder modules. In the simplest of cases, the encoder outputs a single, fixed-sized embedding for the entire input sequence, which we’ll call \(\boldsymbol{a}\), and the decoder, e.g. an RNN, is initialised with this embedding. More precisely, the RNN initial state \(\boldsymbol{h}_0\) is set to the encoder output, or a (non-)linear projection thereof:
In most cases, however, we deal with more sophisticated architectures, and conditioning is realised through fusion of audio and text representations. Earlier models with RNN-based text decoders employ a range of fusion mechanisms, such as feature concatenation or cross-modal attention [MBQF21]. Concatenation as a modality fusion mechanism in RNNs typically consists of concatenating an audio embedding (e.g. the output of the encoder module \(\boldsymbol{a}\)) to the input \(\boldsymbol{x}\), so that an RNN state \(\boldsymbol{h}\) depends on \([\boldsymbol{a}; \boldsymbol{x}]\), or to the previous state vector \([\boldsymbol{a}; \boldsymbol{h}_{t-1}]\), and sometimes to both. In this case, we assume that the encoder produces a single audio embedding.
If our encoder produces instead a sequence of audio embeddings, and we wish to retain the sequential nature of the conditioning signal, an alternative way to achieve fusion is through cross-attention. In this case, instead of concatenating the same audio embedding at every time step \(t\), we can compute attention scores \(\beta_{t i}\) to suitably weigh each item in the audio sequence \(\boldsymbol{a}_i\) differently at each time step \(t\):
where the attention scores are given by
The exact computation of \(e_{t i}\) depends on the score function used. For example, we can have:
where \(\boldsymbol{w}_{a t t}\) and \(\boldsymbol{W}^{a t t}\) are learnable parameters.
Similar types of attention-based fusion can also be used in Transformer-based architectures [GHE22] [DCLN23]. In this setting, instead of the cross-attention shown above, fusion can also be directly embedded within the Transformer blocks by modifying their self-attention mechanism to depend on both text and audio embeddings, though exact implementations of co-attentional Transformer layers vary between models:
In addition to the type of mechanism used, depending on the level at which modalities are combined, it is also common to distinguish between early (i.e. at the input level), intermediate (at the level of latent representations produced by an intermediate step in the overall processing pipeline) or late fusion (i.e. at the output level). We note that the terms early, intermediate and late fusion do not have an unequivocal definition and are used slightly differently in different works.
Multimodal AR Models#
The success of Large Language Models (LLMs) has largely influenced the development of music description in recent years. As a consequence, today’s state-of-the-art models rely on LLMs in one form or another. Typically, this means that music description systems closely mimic text-only autoregressive modelling via Transformers, but within this framework there are two main routes we can take. The first, and most common, is to adapt text-only LLMs so that they become multimodal by augmenting them with additional modelling components. We call these adapted LLMs. A second option is to instead treat audio and text as sequences of tokens from the start, devising tokenization techniques and training on multiple modalities without additional modality-specific components. The line between these two approaches is not always clear. In the next section, we attempt to better define the salient characteristics of LLMs adapted to music-language inputs, and sketch out the newer trend towards natively multimodal models and its potential in music description.
Overall, a common thread in this line of work is the attempt to unify multimodal tasks by reframing all as text generation. When trained on music data, multimodal LLMs can therefore leverage their text-based interface to enable a variety of music understanding and description tasks by simply allowing users to query via text and obtain information about a given audio input. This is the mechanism that enables the conversation-based music description tasks we have seen in the Tasks section.
Adapted LLMs#
One modelling paradigm that has become particularly popular in audio description, including music, is that of adapted (multimodal) LLMs. At the core of this approach is a pre-trained text-only LLM, which is adapted to take in inputs of different modalities such as audio. This is achieved via an adapter module, a light-weight neural network trained to map embeddings produced by an audio feature extractor (usually pre-trained and then frozen) to the input space of the LLM. As a result of this adaptation process, the LLM can then receive audio embeddings alongside text embeddings.
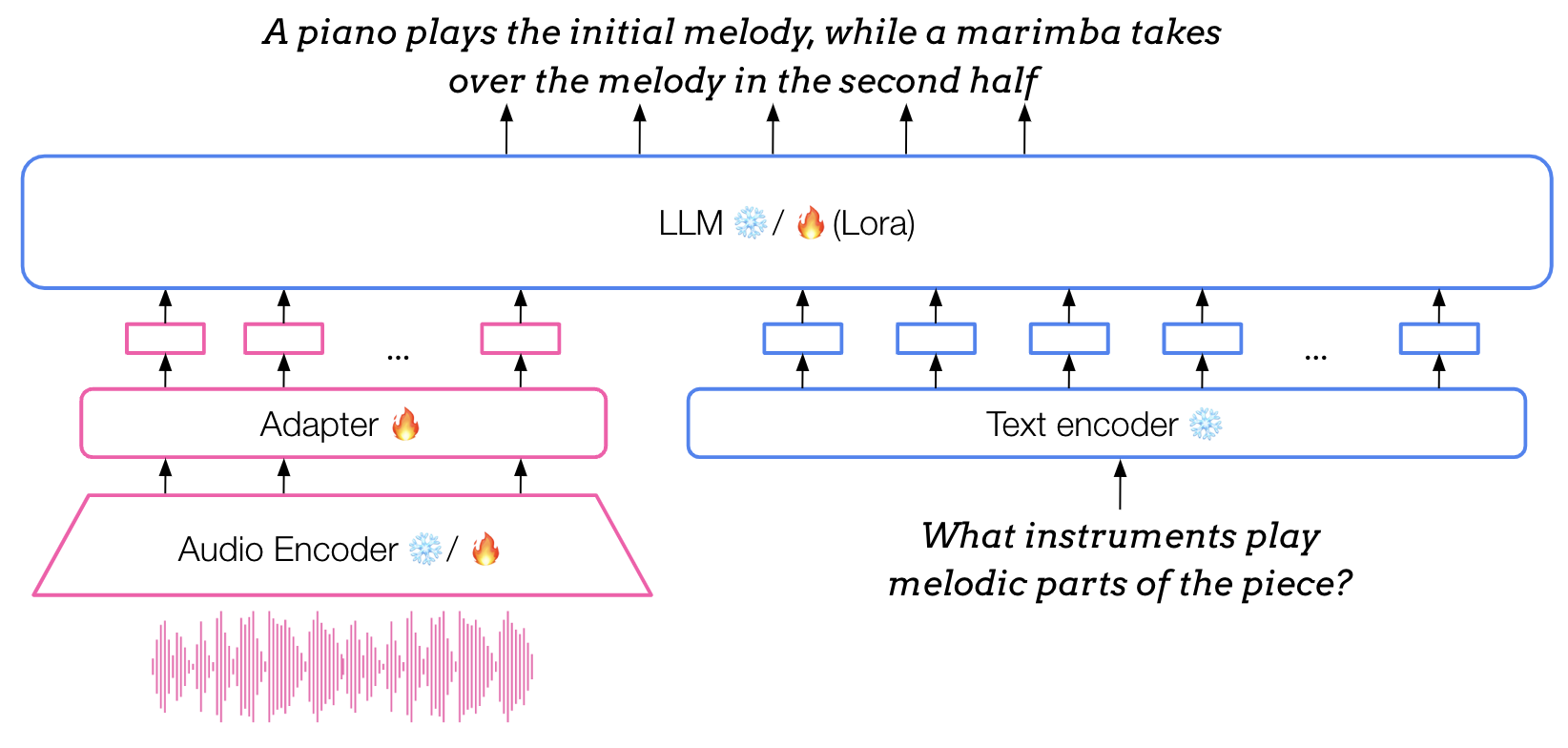
The architecture of the adapter modules employed in adapted LLMs for music typically consists of lightweight MLPs (between 2 and 3 hidden layers) or Q-Formers. Other architectures utilised in general audio adapted LLMs (or similar models in the visual domain) also include more complex designs such as Gated XATTN dense layers. This blog post about Visual Language Models reviews these in more detail.
From the perspective of training, similarly to the text-only setting, training adapted LLMs is usually broken into several stages. After pre-training and finetuning of the text-only part, the remaining components undergo a series of multimodal training stages, while the backbone LLM is either kept frozen or further finetuned. These steps are usually a mixture of multi-task pre-training and supervised finetuning, often including instruction tuning, all carried out on pairs of audio and text data.
Alongside music-specialised multimodal LLMs such as those in Table 1, LLMs with general-audio understanding capabilities can similarly perform music description tasks such as captioning and MQA. Among these we count:
Natively Multimodal AR Models#
Adapted LLMs allow to transform text-only LLMs into multimodal models relatively efficiently: based on the models discussed in this section, around 20-150k audio-text paired samples are required to perform the adaptation stage of training, while multimodal pre-training would require orders of magnitude more data. However, this also limits their performance and often results in a bias towards the language modality and poor audio and music understanding capabilities [WMB+24]. An alternative that promises to overcome this limitation is to instead adopt a natively multimodal approach to AR modelling. One key difference is that, while adapted LLMs require modality-specific encoders, usually pre-trained separately, natively multimodal LLMs forgo this in favour of a unified tokenization scheme that treats audio tokens much like text tokens from the start. This paradigm is sometimes referred to as mixed-modal early-fusion modelling.
It’s worth noting that, at this time, this type of model is a promising direction for music description, rather than a fully established paradigm. Currently, no music-specialised multimodal AR Transformers exist, but some general-purpose models, such as AnyGPT [ZDY+24], include music-domain data in their training and evaluation. This is in line with the overall trend of developing large-scale models that tackle all domains, but it remains to be seen what the impact of this modalling paradigm will be on music description in the years to come.
References#
Keunwoo Choi, George Fazekas, and Mark Sandler. Towards music captioning: generating music playlist descriptions. In Extended abstracts for the Late-Breaking Demo Session of the 17th International Society for Music Information Retrieval Conference. 08 2016. doi:10.48550/arXiv.1608.04868.
Yunfei Chu, Jin Xu, Xiaohuan Zhou, Qian Yang, Shiliang Zhang, Zhijie Yan, Chang Zhou, and Jingren Zhou. Qwen-Audio: Advancing Universal Audio Understanding via Unified Large-Scale Audio-Language Models. December 2023. arXiv:2311.07919 [cs, eess]. URL: http://arxiv.org/abs/2311.07919 (visited on 2024-02-26), doi:10.48550/arXiv.2311.07919.
Zihao Deng, Yinghao Ma, Yudong Liu, Rongchen Guo, Ge Zhang, Wenhu Chen, Wenhao Huang, and Emmanouil Benetos. MusiLingo: Bridging Music and Text with Pre-trained Language Models for Music Captioning and Query Response. In Kevin Duh, Helena Gomez, and Steven Bethard, editors, Findings of the Association for Computational Linguistics: NAACL 2024, 3643–3655. Mexico City, Mexico, June 2024. Association for Computational Linguistics. URL: https://aclanthology.org/2024.findings-naacl.231 (visited on 2024-07-04).
Soham Deshmukh, Benjamin Elizalde, Rita Singh, and Huaming Wang. Pengi: An Audio Language Model for Audio Tasks. In Thirty-seventh Conference on Neural Information Processing Systems. 2023. arXiv:2305.11834 [cs, eess]. URL: http://arxiv.org/abs/2305.11834 (visited on 2024-02-16), doi:10.48550/arXiv.2305.11834.
SeungHeon Doh, Keunwoo Choi, Jongpil Lee, and Juhan Nam. Lp-musiccaps: llm-based pseudo music captioning. In International Society for Music Information Retrieval (ISMIR). 2023.
Giovanni Gabbolini, Romain Hennequin, and Elena Epure. Data-efficient playlist captioning with musical and linguistic knowledge. In Yoav Goldberg, Zornitsa Kozareva, and Yue Zhang, editors, Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, 11401–11415. Abu Dhabi, United Arab Emirates, December 2022. Association for Computational Linguistics. URL: https://aclanthology.org/2022.emnlp-main.784, doi:10.18653/v1/2022.emnlp-main.784.
Josh Gardner, Simon Durand, Daniel Stoller, and Rachel M Bittner. Llark: a multimodal foundation model for music. arXiv preprint arXiv:2310.07160, 2023.
Yuan Gong, Hongyin Luo, Alexander H Liu, Leonid Karlinsky, and James Glass. Listen, think, and understand. arXiv preprint arXiv:2305.10790, 2023.
Zihao He, Weituo Hao, Wei-Tsung Lu, Changyou Chen, Kristina Lerman, and Xuchen Song. Alcap: alignment-augmented music captioner. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, 16501–16512. 2023.
Atin Sakkeer Hussain, Shansong Liu, Chenshuo Sun, and Ying Shan. M2UGen: Multi-modal Music Understanding and Generation with the Power of Large Language Models. arXiv preprint arXiv:2311.11255, 2023.
Zhifeng Kong, Arushi Goel, Rohan Badlani, Wei Ping, Rafael Valle, and Bryan Catanzaro. Audio flamingo: a novel audio language model with few-shot learning and dialogue abilities. In ICML. 2024. URL: https://openreview.net/forum?id=WYi3WKZjYe.
Luca A Lanzendorfer, Nathanal Perraudin, Constantin Pinkl, and Roger Wattenhofer. BLAP: Bootstrapping Language-Audio Pre-training for Music Captioning. In Workshop on AI-Driven Speech, Music, and Sound Generation. 2024.
Dongting Li, Chenchong Tang, and Han Liu. Audio-llm: activating theâ capabilities ofâ large language models toâ comprehend audio data. In Xinyi Le and Zhijun Zhang, editors, Advances in Neural Networks – ISNN 2024, 133–142. Singapore, 2024. Springer Nature Singapore.
Shansong Liu, Atin Sakkeer Hussain, Chenshuo Sun, and Ying Shan. Music understanding llama: advancing text-to-music generation with question answering and captioning. In ICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), volume, 286–290. 2024. doi:10.1109/ICASSP48485.2024.10447027.
Ilaria Manco, Emmanouil Benetos, Elio Quinton, and György Fazekas. Muscaps: generating captions for music audio. In 2021 International Joint Conference on Neural Networks (IJCNN), 1–8. IEEE, 2021.
Nikita Srivatsan, Ke Chen, Shlomo Dubnov, and Taylor Berg-Kirkpatrick. Retrieval guided music captioning via multimodal prefixes. In Kate Larson, editor, Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence, IJCAI-24, 7762–7770. International Joint Conferences on Artificial Intelligence Organization, 8 2024. AI, Arts & Creativity. URL: https://doi.org/10.24963/ijcai.2024/859, doi:10.24963/ijcai.2024/859.
Changli Tang, Wenyi Yu, Guangzhi Sun, Xianzhao Chen, Tian Tan, Wei Li, Lu Lu, Zejun Ma, and Chao Zhang. SALMONN: Towards Generic Hearing Abilities for Large Language Models. In The Twelfth International Conference on Learning Representations. October 2023. URL: https://openreview.net/forum?id=14rn7HpKVk (visited on 2024-02-22).
Benno Weck, Ilaria Manco, Emmanouil Benetos, Elio Quinton, George Fazekas, and Dmitry Bogdanov. MuChoMusic: Evaluating Music Understanding in Multimodal Audio-Language Models. In 25th International Society for Music Information Retrieval Conference. August 2024. arXiv:2408.01337 [cs, eess]. URL: http://arxiv.org/abs/2408.01337 (visited on 2024-08-21), doi:10.48550/arXiv.2408.01337.
Junda Wu, Zachary Novack, Amit Namburi, Jiaheng Dai, Hao-Wen Dong, Zhouhang Xie, Carol Chen, and Julian McAuley. Futga: towards fine-grained music understanding through temporally-enhanced generative augmentation. arXiv preprint arXiv:2407.20445, 2024.
Jun Zhan, Junqi Dai, Jiasheng Ye, Yunhua Zhou, Dong Zhang, Zhigeng Liu, Xin Zhang, Ruibin Yuan, Ge Zhang, Linyang Li, Hang Yan, Jie Fu, Tao Gui, Tianxiang Sun, Yu-Gang Jiang, and Xipeng Qiu. AnyGPT: unified multimodal LLM with discrete sequence modeling. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors, Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 9637–9662. Bangkok, Thailand, August 2024. Association for Computational Linguistics. URL: https://aclanthology.org/2024.acl-long.521, doi:10.18653/v1/2024.acl-long.521.
Mengjie Zhao, Zhi Zhong, Zhuoyuan Mao, Shiqi Yang, Wei-Hsiang Liao, Shusuke Takahashi, Hiromi Wakaki, and Yuki Mitsufuji. Openmu: your swiss army knife for music understanding. arXiv preprint arXiv:2410.15573, 2024.