Evaluation#
Evaluating music retrieval systems is crucial for understanding their effectiveness in returning relevant results that satisfy user queries. The evaluation process requires careful consideration of multiple factors and follows several key steps:
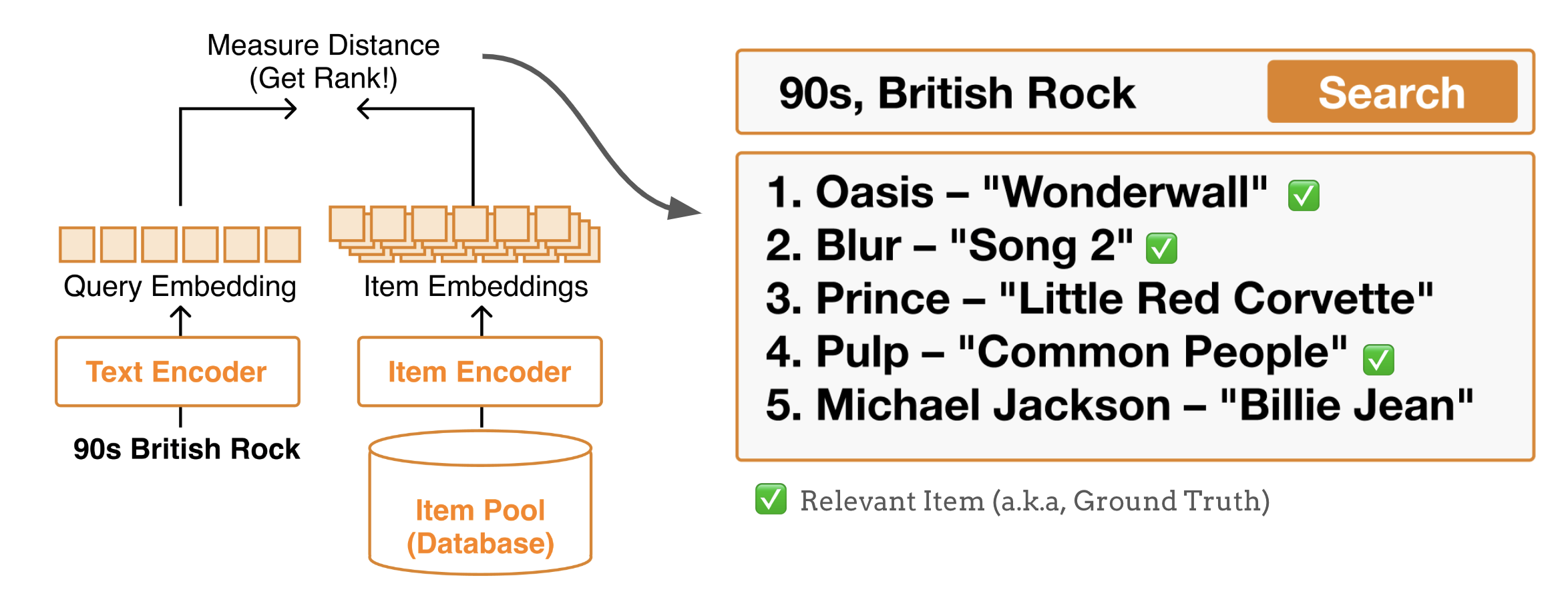
Measure Distance/Similarity: Calculate similarity or distance scores between the query and all items in the database to establish a complete ranking. This involves:
Computing embeddings for both the text query and all music items in the database
Measuring distances using appropriate metrics like cosine similarity, Euclidean distance, or learned similarity functions
Creating a ranked list by sorting items based on their similarity scores
Normalizing scores when necessary to ensure fair comparisons
Define Top K Threshold: Set a cutoff point K that determines which items are considered “retrieved”. This threshold is critical because:
It defines the scope of evaluation - only items ranked within top K are analyzed
It needs to balance between being too restrictive (small K) or too lenient (large K)
It should reflect real-world usage patterns (e.g., users rarely look beyond first few results)
Key concepts include:
Relevant Item: A music piece that appropriately matches the given text query based on predefined criteria
Top K Results: The K highest-ranked items returned by the retrieval system
Predicted Label: Binary indicator (0/1) showing whether the system ranks an item within top K
Actual Label: Ground truth binary indicator showing whether an item should be considered relevant

Evaluate Predictions: Compare system predictions against ground truth labels to identify four key categories:
True Positives (TP): Relevant items correctly ranked within top K
False Positives (FP): Irrelevant items incorrectly ranked within top K
True Negatives (TN): Irrelevant items correctly ranked below top K
False Negatives (FN): Relevant items incorrectly ranked below top K
Calculate Metrics: Use these counts to compute standard evaluation metrics:
Precision and recall for overall accuracy assessment
Ranking-based metrics like MAP@K and MRR for ranking quality
Precision and Recall#
Precision and recall are fundamental metrics that provide complementary information about system performance:
Precision: The proportion of retrieved items that are relevant
Higher precision means fewer irrelevant results in top K
Critical for user satisfaction as it measures result quality
Recall: The proportion of relevant items that are retrieved
Higher recall means fewer missed relevant items
Important for comprehensive retrieval tasks
Mean Average Precision (MAP@K)
Measures the average precision across multiple queries, considering only top K results
Emphasizes returning relevant items earlier in the ranking where AP@K is the average precision at K for a single query
Values range from 0 to 1, with 1 being perfect ranking
Mean Reciprocal Rank (MRR)
Average of the reciprocal ranks of the first relevant result for each query
Focuses on how quickly the system can return at least one relevant result where rank_q is the position of the first relevant result for query q
Particularly useful for tasks where finding first relevant result is crucial
Median Rank
The median position of relevant items in the ranked results
Provides a robust measure of central tendency
Less sensitive to outliers compared to mean rank
Lower values indicate better performance
By carefully considering these evaluation metrics and practices, researchers and practitioners can better understand and improve the performance of music retrieval systems. Regular evaluation using these comprehensive metrics helps ensure that systems meet user needs and perform reliably across different scenarios.