Code Practice#
Welcome to the online supplement for the tutorial on “Connecting Music Audio and Natural Language”
Introduction#
Have you ever imagined an AI that can understand a piece of music and find relevant music? Today, that’s exactly what we’re going to build! Using PyTorch and Hugging Face, we’ll create a music retrieval model (query-by-description), allowing users to search and explore music through natural language queries.
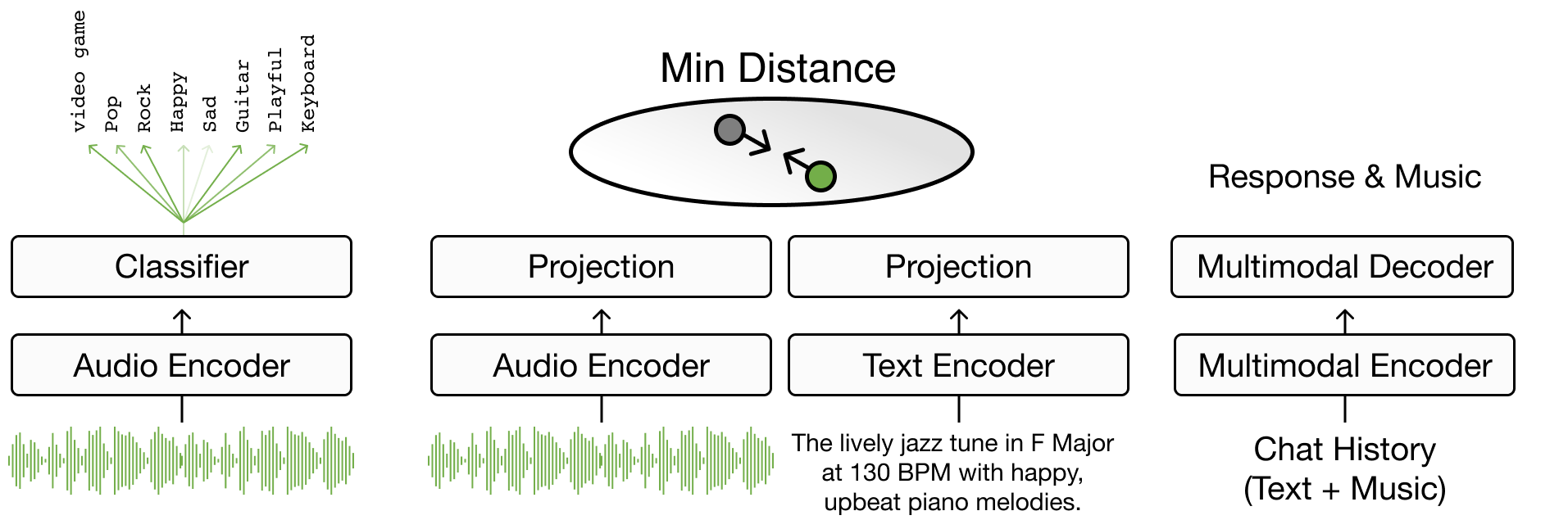
What We’ll Build#
Today, we make a second model!
Audio Encoder: MusicFM, Minz et al. A Foundation Model for Music Informatics
Text Decoder: Roberta-based, Yinhan Liu et al. RoBERTa: A Robustly Optimized BERT Pretraining Approach
By the end of this tutorial, you’ll have:
A working music retrieval model with pretrain music model (MusicFM) and pretrain language model (Roberta)
We use contrastive based training
Prerequisites#
Basic Python knowledge
Familiarity with deep learning concepts
Google Colab account (free!)
Let’s Get Started! 🚀#
Step 1: Setting Up Our Environment#
First, let’s set up our Google Colab environment. Create a new notebook and make sure you’ve got that GPU runtime enabled (trust me, you’ll want it!).
import torch
print("GPU Available:", torch.cuda.is_available())
print("GPU Device Name:", torch.cuda.get_device_name(0) if torch.cuda.is_available() else "No GPU")
GPU Available: False
GPU Device Name: No GPU
Step 2: Understanding the Data 📊#
We’ll be using the subset of LP-MusicCaps-MTT dataset. Why this dataset? It’s perfect for learning because:
It’s not too large (3k training set, 300 test set)
10 second CC audio file
💡 Pro Tip: For Original Content, you can download it from LP-MusicCaps-MTT
import torchaudio
import torch.nn as nn
import numpy as np
from tqdm.notebook import tqdm
from transformers import AutoModel, AutoTokenizer
from datasets import load_dataset
from IPython.display import Audio
# Load Magnatagatune Dataset: 1-min
dataset = load_dataset("mulab-mir/lp-music-caps-magnatagatune-3k", split="train")
---------------------------------------------------------------------------
ModuleNotFoundError Traceback (most recent call last)
Cell In[2], line 1
----> 1 import torchaudio
2 import torch.nn as nn
3 import numpy as np
ModuleNotFoundError: No module named 'torchaudio'
print("Original Magnatagatune Tags: ", dataset[10]['tags'])
print("-"*10)
print("LP-MusicCaps Captions: ")
print("\n".join(dataset[10]['texts']))
Audio(dataset[10]['audio']["array"], rate=22050)
Original Magnatagatune Tags: ['vocals', 'female', 'guitar', 'girl', 'pop', 'female vocal', 'rock', 'female vocals', 'female singer']
----------
LP-MusicCaps Captions:
Get ready to be blown away by the powerful and energetic female vocals accompanied by a catchy guitar riff in this upbeat pop-rock anthem, performed by an incredibly talented girl singer with impressive female vocal range.
A catchy pop-rock song featuring strong female vocals and a prominent guitar riff.
Get ready to experience the dynamic and captivating sound of a female singer with powerful vocals, accompanied by the electric strumming of a guitar - this pop/rock tune will have you hooked on the mesmerizing female vocals of this talented girl.
This song is a powerful combination of female vocals, guitar, and rock influences, with a pop beat that keeps the tempo up. The female singer's voice is full of emotion, creating a sense of vulnerability and rawness. The acoustic sound is perfect for a girl's night out, with the melancholic folk vibe that captures the heart of a female vocalist who tells a story through her music.
Step 3: Creating Our Dataset Class 🎨#
Here’s where things get interesting! We need to create a custom dataset class that will:
Load music data (x) and captions (y)
import torch
import random
from torch.utils.data import Dataset
class MusicTextDataset(Dataset):
def __init__(self, split="train"):
self.data = load_dataset("mulab-mir/lp-music-caps-magnatagatune-3k", split=split)
musicfm_embeds = load_dataset("mulab-mir/lp-music-caps-magnatagatune-3k-musicfm-embedding", split=split)
roberta_embeds = load_dataset("mulab-mir/lp-music-caps-magnatagatune-3k-roberta-embedding", split=split)
self.track2embs = {i["track_id"]:i["embedding"] for i in musicfm_embeds}
self.caption2embs = {i["track_id"]:i["embedding"] for i in roberta_embeds}
def __len__(self):
return len(self.data)
def __getitem__(self, index: int):
item = self.data[index]
text = random.choice(item['texts'])
h_audio = torch.tensor(self.track2embs[item['track_id']])
h_text = torch.tensor(self.caption2embs[item['track_id']])
return {
"track_id": item["track_id"],
"text": text,
"h_audio": h_audio,
"h_text": h_text
}
train_dataset = MusicTextDataset(split="train")
test_dataset = MusicTextDataset(split="test")
tr_dataloader = torch.utils.data.DataLoader(train_dataset, batch_size=128, num_workers=0,shuffle=True, drop_last=True)
te_dataloader = torch.utils.data.DataLoader(test_dataset, batch_size=128, num_workers=0, shuffle=False, drop_last=True)
for item in test_dataset:
print(item["track_id"])
print(item["text"])
print(item["h_audio"].shape)
print(item["h_text"].shape)
break
18754
A powerful female Indian vocalist captivates listeners with her mesmerizing rock singing, infusing her foreign roots into an electrifying blend of contemporary sounds, delivering a captivating performance that evades the realm of opera.
torch.Size([1024])
torch.Size([768])
Step 4: Building & Training Our Model Architecture 🏗️#
Now for the exciting part - building our model! We’re going to use a modern architecture that combines:
MusicFM for audio understanding
Roberta for text understnading
Let’s use projection & contrastive connection for music and langauge latent
class JointEmbeddingModel(torch.nn.Module):
def __init__(self, joint_dim=128, temperature=0.07):
super().__init__()
self.joint_dim = joint_dim
self.temperature = temperature
# Add projection part
self.init_temperature = torch.tensor([np.log(1/temperature)])
self.logit_scale = nn.Parameter(self.init_temperature, requires_grad=True)
self.text_embedding_dim = 768 # roberta dim
self.audio_embedding_dim = 1024 # music Fm dim
self.audio_projection = nn.Sequential(
nn.Linear(self.audio_embedding_dim, self.joint_dim, bias=False),
nn.ReLU(),
nn.Linear(self.joint_dim, self.joint_dim, bias=False)
)
self.text_projection = nn.Sequential(
nn.Linear(self.text_embedding_dim, self.joint_dim, bias=False),
nn.ReLU(),
nn.Linear(self.joint_dim, self.joint_dim, bias=False)
)
@property
def device(self):
return list(self.parameters())[0].device
@property
def dtype(self):
return list(self.parameters())[0].dtype
def audio_forward(self, h_audio):
z_audio = self.audio_projection(h_audio)
return z_audio
def text_forward(self, h_text):
z_text = self.text_projection(h_text)
return z_text
def simple_contrastive_loss(self, z1, z2):
z1 = nn.functional.normalize(z1, dim=1)
z2 = nn.functional.normalize(z2, dim=1)
temperature = torch.clamp(self.logit_scale.exp(), max=100)
logits = torch.einsum('nc,mc->nm', [z1, z2]) * temperature.to(self.device)
N = logits.shape[0] # batch size per GPU
labels = torch.arange(N, dtype=torch.long, device=self.device)
return torch.nn.functional.cross_entropy(logits, labels)
def forward(self, batch):
z_audio = self.audio_forward(batch['h_audio'].to(self.device))
z_text = self.text_forward(batch['h_text'].to(self.device))
loss_a2t = self.simple_contrastive_loss(z_audio, z_text)
loss_t2a = self.simple_contrastive_loss(z_text, z_audio)
loss = (loss_a2t + loss_t2a) / 2
return loss
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = JointEmbeddingModel()
model.to(device)
train_parmas = sum(p.numel() for p in model.parameters() if p.requires_grad)
freeze_parmas = sum(p.numel() for p in model.parameters() if not p.requires_grad)
print(f"training model with: train_parmas {train_parmas} params, and {freeze_parmas} freeze parmas")
training model with: train_parmas 262145 params, and 0 freeze parmas
def train(model, dataloader, optimizer, epoch):
model.train()
total_loss = 0
pbar = tqdm(dataloader, desc=f'TRAIN Epoch {epoch:02}')
for batch in pbar:
optimizer.zero_grad()
loss = model(batch)
loss.backward()
optimizer.step()
total_loss += loss.item()
epoch_loss = total_loss / len(dataloader)
return epoch_loss
def test(model, dataloader):
model.eval()
total_loss = 0
for batch in dataloader:
with torch.no_grad():
loss = model(batch)
total_loss += loss.item()
epoch_loss = total_loss / len(dataloader)
return epoch_loss
NUM_EPOCHS = 10
lr = 1e-2
# Define optimizer and loss function
optimizer = torch.optim.AdamW(model.parameters(), lr=lr)
for epoch in range(NUM_EPOCHS):
train_loss = train(model, tr_dataloader, optimizer, epoch)
valid_loss = test(model, te_dataloader)
print("[Epoch %d/%d] [Train Loss: %.4f] [Valid Loss: %.4f]" % (epoch + 1, NUM_EPOCHS, train_loss, valid_loss))
[Epoch 1/10] [Train Loss: 4.7925] [Valid Loss: 4.4868]
[Epoch 2/10] [Train Loss: 4.3727] [Valid Loss: 4.2788]
[Epoch 3/10] [Train Loss: 4.1146] [Valid Loss: 3.9048]
[Epoch 4/10] [Train Loss: 3.8462] [Valid Loss: 3.7907]
[Epoch 5/10] [Train Loss: 3.6809] [Valid Loss: 3.7047]
[Epoch 6/10] [Train Loss: 3.5244] [Valid Loss: 3.5302]
[Epoch 7/10] [Train Loss: 3.2971] [Valid Loss: 3.5063]
[Epoch 8/10] [Train Loss: 3.1679] [Valid Loss: 3.3523]
[Epoch 9/10] [Train Loss: 3.0083] [Valid Loss: 3.3572]
[Epoch 10/10] [Train Loss: 2.9240] [Valid Loss: 3.2919]
Inference & Make Retrieval Engine#
Load Model & Embedding
Extract Item Embedding Database (a.k.a Vector Database)
Extract Query Embedding
Measure Distance (Similarity)
# load model
model.eval()
print("let's start inference!")
let's start inference!
# bulid metadata db
dataset = load_dataset("mulab-mir/lp-music-caps-magnatagatune-3k", split="test")
meta_db = {i["track_id"]:i for i in tqdm(dataset)}
def get_item_vector_db(model, dataloader):
track_ids, audios, item_joint_embedding = [], [], []
for item in tqdm(dataloader):
h_audio = item['h_audio']
with torch.no_grad():
z_audio = model.audio_forward(h_audio.to(model.device))
item_joint_embedding.append(z_audio.detach().cpu())
track_ids.extend(item['track_id'])
item_vector_db = torch.cat(item_joint_embedding, dim=0)
return item_vector_db, track_ids
item_vector_db, track_ids = get_item_vector_db(model, te_dataloader)
text_encoder = AutoModel.from_pretrained("roberta-base").to(device)
text_tokenizer = AutoTokenizer.from_pretrained("roberta-base")
/usr/local/lib/python3.10/dist-packages/transformers/tokenization_utils_base.py:1601: FutureWarning: `clean_up_tokenization_spaces` was not set. It will be set to `True` by default. This behavior will be depracted in transformers v4.45, and will be then set to `False` by default. For more details check this issue: https://github.com/huggingface/transformers/issues/31884
warnings.warn(
def get_query_embedding(query, model, text_encoder, text_tokenizer):
encode = text_tokenizer([query],
padding='longest',
truncation=True,
max_length=128,
return_tensors="pt")
input_ids = encode["input_ids"].to(device)
attention_mask = encode["attention_mask"].to(device)
with torch.no_grad():
text_output = text_encoder(input_ids=input_ids , attention_mask=attention_mask)
h_text = text_output["last_hidden_state"].mean(dim=1)
z_text = model.text_forward(h_text)
query_vector = z_text.detach().cpu()
return query_vector
def retrieval_fn(query, model, item_vector_db, topk=3):
query_vector = get_query_embedding(query, model, text_encoder, text_tokenizer)
query_vector = nn.functional.normalize(query_vector, dim=1)
item_vector_db = nn.functional.normalize(item_vector_db, dim=1)
similarity_metrics = query_vector @ item_vector_db.T
_, indices = torch.topk(similarity_metrics, k=topk)
for i in indices.flatten():
item = meta_db[track_ids[i]]
print("track_id: ", item['track_id'])
print("ground truth tags: ", item["tags"])
display(Audio(item["audio"]["array"], rate=22050))
query = "country guitar with no vocal"
indices = retrieval_fn(query, model, item_vector_db)
track_id: 46649
ground truth tags: ['guitar', 'banjo', 'folk', 'strings', 'country', 'no vocals']
track_id: 48072
ground truth tags: ['no voice', 'guitar', 'strings', 'country', 'violin']
track_id: 33437
ground truth tags: ['duet', 'classical', 'guitar', 'acoustic', 'classical guitar', 'no vocals', 'spanish', 'slow']
Conclusion 🎉#
Congratulations! You’ve built a complete query-by-description system. But this is just the beginning - there are many ways to improve and extend this model:
Try different architectures
Experiment with larger datasets
Implement better evaluation metrics
Resources for Further Learning 📚#
Now go forth and build amazing things! 🌟