Why Natural Langauge?#
1. Natural Langauge is (almost) universal label (y), task (z) encoder.#
The greatest advantage of language is its ability to represent a wide variety of Music Information Retrieval (MIR) labels and tasks in a unified space. Furthermore, with the advancement of language models, this unified space is not orthogonal (like one-hot encoding) but learns relative meanings from the huge corpora used in pre-training language models. This allows for a more nuanced and contextual representation of musical concepts and tasks.
This flexible ability to represent
tasksandlabelsallows the music-language model to understand a wider variety of tasks simultaneously, rather than being limited to a single task, which enables it to become a more generalized model.Thanks to this ability, music-language models can possess the ability to solve out-of-vocabulary problems and handle novel classes.
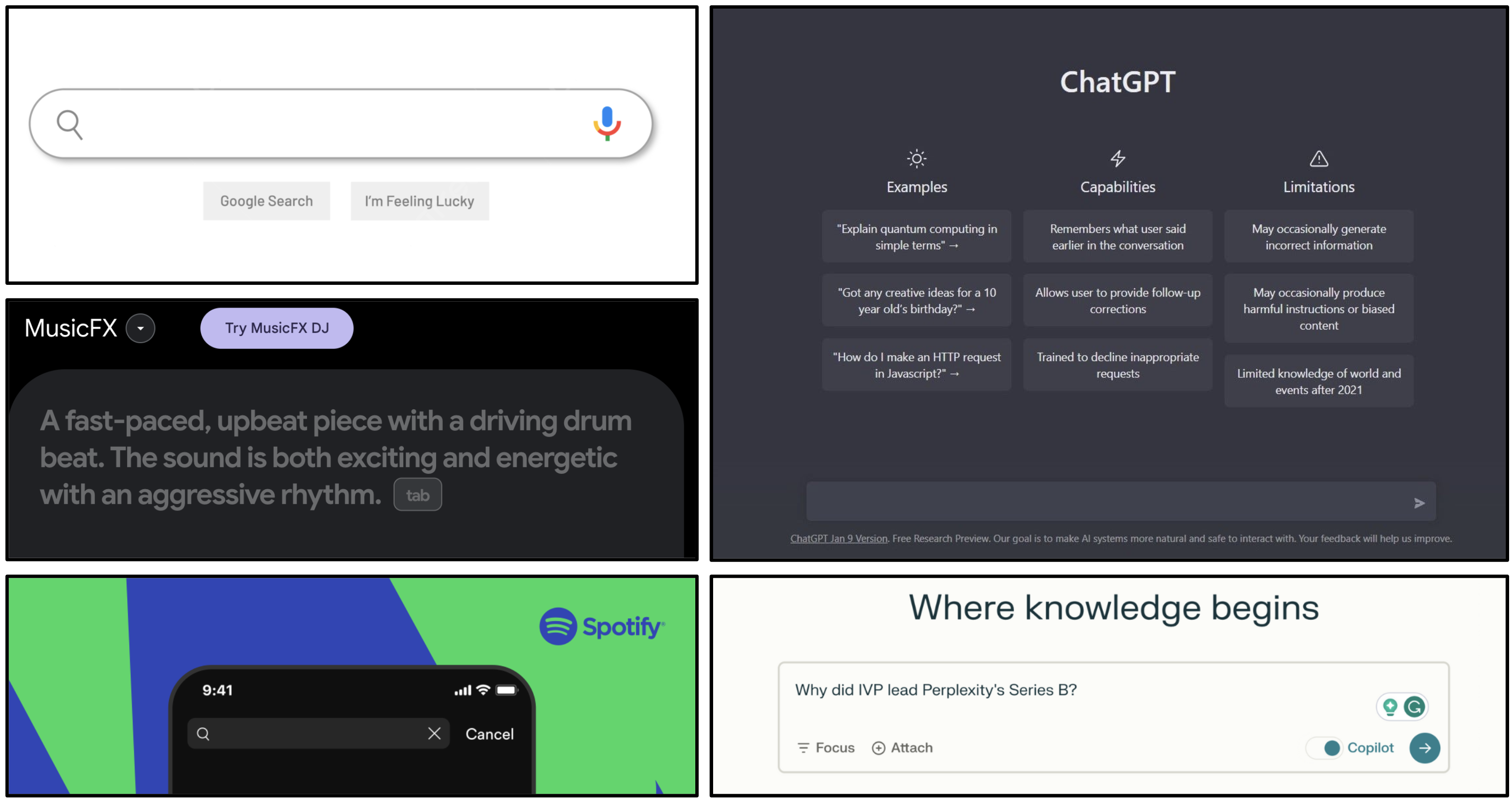
While we will learn about the detailed development of language models in Chapter 2, let’s briefly check an example of the advantages mentioned above using a pre-trained language model. We can visualize through T-SNE that various models’ labels and tasks can be expressed in language, and that they exist in the same space.
import warnings
warnings.filterwarnings('ignore')
import torch
import numpy as np
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('sentence-transformers/sentence-t5-base')
y = ["rock music", "rap music", "classical music", "130bpm", "120bpm" ,"55bpm", "piano", "electronic guitar", "acoustic guitar", "aggressive", "happy", "excited", "bright sound", "dark sound", "soft sound"]
z = ['genre', 'tempo', 'instrument', 'mood', 'timbre']
with torch.no_grad():
embeddings = model.encode(y + z)
embeddings = embeddings / np.linalg.norm(embeddings, axis=1, keepdims=True)
---------------------------------------------------------------------------
ModuleNotFoundError Traceback (most recent call last)
Cell In[1], line 5
3 import torch
4 import numpy as np
----> 5 from sklearn.manifold import TSNE
6 import matplotlib.pyplot as plt
7 from sentence_transformers import SentenceTransformer
ModuleNotFoundError: No module named 'sklearn'
tsne = TSNE(n_components=2, random_state=42, perplexity=5)
embeddings_2d = tsne.fit_transform(embeddings)
plt.figure(figsize=(12, 8))
colors = {'label(y)': 'blue', 'task(z)': 'green'}
for i, text in enumerate(y + z):
color = colors['label(y)'] if i < len(y) else colors['task(z)']
plt.scatter(embeddings_2d[i, 0], embeddings_2d[i, 1], c=color, s=150)
plt.annotate(text, (embeddings_2d[i, 0] - 3, embeddings_2d[i, 1] + 2), fontsize=13)
plt.title("t-SNE visualization of music-related text embeddings", fontsize=16)
plt.legend(handles=[plt.Line2D([0], [0], marker='o', color='w', label=cat, markerfacecolor=color, markersize=12) for cat, color in colors.items()], fontsize=12)
plt.tight_layout()
plt.show()
2. Natural Langauge is (weak but scalable) supervision for representation learning#
Although it’s not within the scope of this tutorial (which focuses on annotation, retrieval, and generation tasks), music-language models can become powerful representation learners by using high-level semantic information as supervision. Models trained on noisy but scalable music-text pairs can perform well on downstream tasks. For example, in the vision domain, models like CLIP (Contrastive Language-Image Pre-training) [RKH+21] and CoCa (Contrastive Captioners are Image-Text Foundation Models) [YWV+22] actually report excellent performance on multiple downstream tasks. In the music domain, the MuLaP [MBQF22b], TTMR [DWCN23], and MuLan [HJL+22] papers demonstrate that Music-Language models can be powerful representation learners.
Additionally, many people try “dancing about architecture”. In reality, a lot of music metadata, review, social tags, high-level to low-level attribute descriptions, lyrics, etc. remain as natural language data. We will cover more details about this in the dataset section. Additionally, we can use labels inferred from other pretrained MIR models as pseudo labels [GDSB23]. This can be seen as a weaker but still scalable form of supervision compared to self-supervision.
Note
The phrase “Writing about music is like dancing about architecture” is often used to describe the difficulty of expressing music through words.
3. Natural Langauge is Human Friendly interface.#
Language serves as an effective interface for AI models, (i.e., ChatGPT and Stable Diffusion). Because it leverages natural, intuitive communication methods. Language allows users to express complex queries, requests, or ideas in a flexible and contextually rich way without needing specialized knowledge. In terms of responses, language can also enable the system to generate human-like intentions or answers, which can positively impact user satisfaction and usability.